

Nos Publications
2025
Applied Mathematics and Computation, 2025, vol. 490, p. 129173, 2025
abstract
Abstract
In this paper, we propose a new class of second-order one-step time-splitting schemes for scalar and systems of conservation laws. The strategy is based on a relaxation approximation which consists in introducing a relaxation system with linearly degenerate characteristic fields to approximate the original system and deal with its nonlinearities. The numerical schemes are based on the use of arbitrarily high-order approximations of the underlying linear advection equations. Numerical evidence is proposed to illustrate the behaviour of our schemes.
International Journal for Numerical Methods in Engineering, Volume126, e70051, 2025
abstract
Abstract
In this article, we propose and investigate an explicit partitioned method for solving shock dynamics in fluid–structure interaction (FSI) problems. The method is fully conservative, ensuring the local conservation of mass, momentum, and energy, which is crucial for accurately capturing strong shock interactions. Using an updated-Lagrangian finite-volume approach, the method integrates a subcycling strategy to decouple time steps between the fluid and structure, significantly enhancing computational efficiency. Numerical experiments confirm the accuracy and stability of the method, demonstrating that it retains the key properties of monolithic solvers while reducing computational costs. Extensive validation across 1D and 3D FSI problems shows the method's capability for large-scale, fast transient simulations, making it a promising solution for high-performance applications.
Computers & Fluids, Volume 297, 106648, 2025
abstract
Abstract
In this paper, we present an extension to non-uniform meshes of a 1D scheme [Rémi Abgrall and Davide Torlo. “Some preliminary results on a high order asymptotic preserving computationally explicit kinetic scheme”. In: Abgrall and Torlo (2022). This scheme is arbitrary high order convergent in space and time for any hyperbolic system of conservation laws. It is based on a Finite Difference technique. We show that this numerical method is not conservative but it satisfies a Lax–Wendroff theorem under restrictive conditions on the mesh. To relax this condition we propose a Finite Volume alternative. This new discretization can be seen as a direct generalization to non-uniform meshes of the Finite Difference schemes in the sense that the fluxes of both methods are the same on uniform meshes. We apply the two schemes to the Euler system and we assess their performances on regarding test problems of the literature.
2024
2024
abstract
Abstract
This animation has been realized using ParaView [1] and aims to demonstrate the different steps of an algorithm developed to generate block-structured meshes suitable for Computational Fluid Dynamics simulations of flows around vehicles during atmospheric re-entry. This method takes a tetrahedral mesh of the domain as input and the quadrangular block discretization of the vehicle surface. A linear blocking is obtained using an advancing front algorithm. This means it is incrementally created from the vehicle surface, layer by layer. Some distance and vector fields are computed on the tetrahedral mesh to lead the block's extrusion direction. Then, the linear blocking is curved, and the final mesh is generated. The algorithm is freely available and implemented in the open-source C++ meshing framework GMDS [2,3]. The algorithm is based on the previous work of Ruiz-Gironés et al. [4,5]. Details of the algorithm are available in [6,7]. Here, the algorithm generates a mesh around a vehicle with two wings. This block structure is generated on four different layers. The creation of the first layer of blocks is shown here, block by block. [1] https://www.paraview.org/ [2] https://github.com/LIHPC- Computational- Geometry/gmds [3] Franck Ledoux, Jean-Claude Weill, and Yves Bertrand. Gmds: A generic mesh data structure. 17th International Meshing Roundtable, 2008. [4] Eloi Ruiz-Gironés. Automatic hexahedral meshing algorithms: from structured to unstructured meshes. PhD thesis, Universitat Politècnica de Catalunya (UPC), 2011. [5] Eloi Ruiz-Gironés, Xevi Roca, and Josep Sarrate. The receding front method applied to hexahedral mesh generation of exterior domains. Engineering with computers, 28(4):391–408, 2012. [6] Claire Roche, Jérôme Breil, Simon Calderan, Thierry Hocquellet, and Franck Ledoux. Curved hexahedral block structure generation by advancing front. In SIAM International Meshing Roundtable Workshop 2024 (SIAM IMR24), 2024. [7] Claire Roche, Jérôme Breil, Thierry Hocquellet, and Franck Ledoux. Block-structured quad meshing for supersonic flow simulations. In SIAM International Meshing Roundtable Workshop 2023 (SIAM IMR23), Amsterdam, The Netherlands, March 2023.
European MPI Users' Group Meeting, 2024
abstract
Abstract
The evolution of parallel computing architectures presents new challenges for developing efficient parallelized codes. The emergence of heterogeneous systems has given rise to multiple programming models, each requiring careful adaptation to maximize performance. In this context, we propose reevaluating memory layout designs for computational tasks within larger nodes by comparing various architectures. To gain insight into the performance discrepancies between shared memory and shared-address space settings, we systematically measure the bandwidth between cores and sockets using different methodologies. Our findings reveal significant differences in performance, suggesting that MPI running inside UNIX processes may not fully utilize its intranode bandwidth potential. In light of our work in the MPC thread-based MPI runtime, which can leverage shared memory to achieve higher performance due to its optimized layout, we advocate for enabling the use of shared memory within the MPI standard.
15th International Conference on Parallel Processing & Applied Mathematics, 2024
abstract
Abstract
Breaking down the parallel time into work, idleness, and overheads is crucial for assessing the performance of HPC applications, but difficult to measure in asynchronous dependent tasking runtime systems. No existing tools allow its measurement portably and accurately. This paper introduces POT: a tool-suite for dependent task-based applications performance measurement. We focus on its low-disturbance methodology consisting of task modeling, discrete-event tracing, and post-mortem simulation-based analysis. It supports the OMPT standard OpenMP specifications. The paper evaluates the precision of POT's parallel time breakdown analysis on LLVM and MPC implementations and shows that measurement bias may be neglected above 16µs workload per task, portably across two architectures and OpenMP runtime systems
HPCAsia 2024 Workshops Proceedings of the International Conference on High Performance Computing in Asia-Pacific Region Workshops, 2024
abstract
Abstract
The adoption of ARM processor architectures is on the rise in the HPC ecosystem. Fugaku supercomputer is a homogeneous ARMbased machine, and is one among the most powerful machine in the world. In the programming world, dependent task-based programming models are gaining tractions due to their many advantages like dynamic load balancing, implicit expression of communication/computation overlap, early-bird communication posting,... MPI and OpenMP are two widespreads programming standards that make possible task-based programming at a distributed memory level. Despite its many advantages, mixed-use of the standard programming models using dependent tasks is still under-evaluated on large-scale machines. In this paper, we provide an overview on mixing OpenMP dependent tasking model with MPI with the state-of-the-art software stack (GCC-13, Clang17, MPC-OMP). We provide the level of performances to expect by porting applications to such mixed-use of the standard on the Fugaku supercomputers, using two benchmarks (Cholesky, HPCCG) and a proxy-application (LULESH). We show that software stack, resource binding and communication progression mechanisms are factors that have a significant impact on performance. On distributed applications, performances reaches up to 80% of effiency for task-based applications like HPCCG. We also point-out a few areas of improvements in OpenMP runtimes.
Computers & Mathematics with Applications, Volume 158, Pages 56-73, ISSN 0898-1221, 2024
abstract
Abstract
We propose in this article a monotone finite volume diffusion scheme on 3D general meshes for the radiation hydrodynamics. Primary unknowns are averaged value over the cells of the mesh. It requires the evaluation of intermediate unknowns located at the vertices of the mesh. These vertex unknowns are computed using an interpolation method. In a second step, the scheme is made monotone by combining the computed fluxes. It allows to recover monotonicity, while making the scheme nonlinear. This scheme is inserted into a radiation hydrodynamics solver and assessed on radiation shock solutions on deformed meshes.
Proceedings of the 2024 International Meshing Roundtable (IMR), 2024
abstract

Abstract
Computational analysis with the finite element method requires geometrically accurate meshes. It is well known that high-order meshes can accurately capture curved surfaces with fewer degrees of freedom in comparison to low-order meshes. Existing techniques for high-order mesh generation typically output meshes with same polynomial order for all elements. However, high order elements away from curvilinear boundaries or interfaces increase the computational cost of the simulation without increasing geometric accuracy. In prior work [5, 21], we have presented one such approach for generating body-fitted uniform-order meshes that takes a given mesh and morphs it to align with the surface of interest prescribed as the zero isocontour of a level-set function. We extend this method to generate mixed-order meshes such that curved surfaces of the domain are discretized with high-order elements, while low-order elements are used elsewhere. Numerical experiments demonstrate the robustness of the approach and show that it can be used to generate mixed-order meshes that are much more efficient than high uniform-order meshes. The proposed approach is purely algebraic, and extends to different types of elements (quadrilaterals/triangles/tetrahedron/hexahedra) in two- and three-dimensions.
Collection PROfil, Editeur EDP Sciences, p. 248, 2024
Journal of Computational Physics, Volume 518, 2024, 113325, ISSN 0021-9991, 2024
abstract
Abstract
Monotonicity is very important in most applications solving elliptic problems. Many schemes preserving positivity has been proposed but are at most second-order convergent. Besides, in general, high-order schemes do not preserve positivity. In the present paper, we propose an arbitrary-order monotonic method for elliptic problems in 2D. We show how to adapt our method to the case of a discontinuous and/or tensorvalued diffusion coefficient, while keeping the order of convergence. We assess the new scheme on several test problems.
Thèse de Doctorat de l'Université Paris-Saclay, 2024
abstract
Abstract
Ce travail de thèse porte sur la représentation et la génération de maillages hexaédriques structurés par blocs. Il n'existe pas à ce jour de méthode permettant de générer des structures de blocs satisfaisantes pour n'importe quel domaine géométrique. En pratique, des ingénieurs experts génèrent ces maillages avec des logiciels interactifs, ce qui nécessite parfois plusieurs semaines de travail. De plus, l'ajout d'opérations de modification dans ces logiciels interactifs est un travail délicat pour maintenir la cohérence de la structure de blocs et sa relation avec le domaine géométrique à discrétiser. Afin d'améliorer ce processus, nous proposons tout d'abord de définir des opérations de manipulation de maillages hexaédriques se basant sur l'utilisation du modèle des cartes généralisées. Ensuite, en considérant des structures de blocs obtenues à l'aide de la méthode des Polycubes, nous fournissons des méthodes optimisant la topologie de ces structures pour satisfaire des contraintes de nature géométrique. Nous proposons ainsi une première méthode en dimension 2, qui considère une approche locale du problème en s'appuyant sur l'expérience des ingénieurs manipulant des logiciels interactifs. Puis nous proposons une seconde méthode utilisant cette fois la méta-heuristique d'optimisation par colonie de fourmis pour la sélection de feuillets en dimension 3.
SIAM IMR24-SIAM International Meshing Roundtable Workshop, 2024
abstract
Abstract
This work aims to provide a method to generate block-structured meshes suitable for Computational Fluid Dynamics (CFD) simulations of flows around vehicles during atmospheric re-entry. This method takes as input a tetrahedral mesh of the domain, and the quadrangular block discretization of the vehicle surface. A linear blocking is obtained using an advancing front algorithm. This means it is incrementally created from the vehicle surface, layer by layer. Then, this linear blocking is curved, and we generate the final mesh. Some results of blocking and corresponding meshes generated with our algorithm are shown.
IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2024
ISPRS Open Journal of Photogrammetry and Remote Sensing, 2024
abstract
Abstract
CNES is currently carrying out a Phase A study to assess the feasibility of a future hyperspectral imaging sensor (10 m spatial resolution) combined with a panchromatic camera (2.5 m spatial resolution). This mission focuses on both high spatial and spectral resolution requirements, as inherited from previous French studies such as HYPEX, HYPXIM, and BIODIVERSITY. To meet user requirements, cost, and instrument compactness constraints, CNES asked the French hyperspectral Mission Advisory Group (MAG), representing a broad French scientific community, to provide recommendations on spectral sampling, particularly in the Short Wave InfraRed (SWIR) for various applications. This paper presents the tests carried out with the aim of defining the optimal spectral sampling and spectral resolution in the SWIR domain for quantitative estimation of physical variables and classification purposes. The targeted applications are geosciences (mineralogy, soil moisture content), forestry (tree species classification, leaf functional traits), coastal and inland waters (bathymetry, water column, bottom classification in shallow water, coastal habitat classification), urban areas (land cover), industrial plumes (aerosols, methane and carbon dioxide), cryosphere (specific surface area, equivalent black carbon concentration), and atmosphere (water vapor, carbon dioxide and aerosols). All the products simulated in this exercise used the same CNES end-to-end processing chain, with realistic instrument parameters, enabling easy comparison between applications. 648 simulations 68 were carried out with different spectral strategies, radiometric calibration performances and signal-to-noise Ratios (SNR): 24 instrument configurations ´ 25 datasets (22 images + 3 spectral libraries). The results show that a 16/20 nm spectral sampling in the SWIR domain is sufficient for most applications. However, 10 nm spectral sampling is recommended for applications based onspecific absorption bands such as mineralogy, industrial plumes or atmospheric gases. In addition, a slight performance loss is generally observed when radiometric calibration accuracy decreases, with a few exceptions in bathymetry and in the cryosphere for which the observed performance is severely degraded. Finally, most applications can be achieved with the lowest SNR, with the exception of bathymetry, shallow water classification, as well as carbon dioxide and methane estimation, which require the higher SNR level tested. On the basis of these results, CNES is currently evaluating the best compromise for designing the future hyperspectral sensor to meet the objectives of priority applications.
Proceedings of the 21st ACM International Conference on Computing Frontiers: Workshops and Special Sessions, Association for Computing Machinery, p. 94-100, 2024
abstract
Abstract
The new emerging scientific workloads to be executed in the upcoming exascale supercomputers face major challenges in terms of storage, given their extreme volume of data. In particular, intelligent data placement, instrumentation, and workflow handling are central to application performance. The IO-SEA project developed multiple solutions to aid the scientific community in adressing these challenges: a Workflow Manager, a hierarchical storage management system, and a semantic API for storage. All of these major products incorporate additional minor products that support their mission. In this paper, we discuss both the roles of all these products and how they can assist the scientific community in achieving exascale performance.
Zenodo, 2024
Euro-Par 2024: Parallel Processing, Springer Nature Switzerland, p. 77-90, 2024
abstract
Abstract
With the advent of heterogeneous systems that combine CPUs and GPUs, designing a supercomputer becomes more and more complex. The hardware characteristics of GPUs significantly impact the performance. Choosing the GPU that will maximize performance for a limited budget is tedious because it requires predicting the performance on a non-existing hardware platform.
Microprocessors and Microsystems, Volume 110, October 2024, 105102, 2024
abstract
Abstract
RED-SEA is a H2020 EuroHPC project, whose main objective is to prepare a new-generation European Interconnect, capable of powering the EU Exascale systems to come, through an economically viable and technologically efficient interconnect, leveraging European interconnect technology (BXI) associated with standard and mature technology (Ethernet), previous EU-funded initiatives, as well as open standards and compatible APIs. To achieve this objective, the RED-SEA project is being carried out around four key pillars: (i) network architecture and workload requirements-interconnects co-design – aiming at optimizing the fit with the other EuroHPC projects and with the EPI processors; (ii) development of a high-performance, low-latency, seamless bridge with Ethernet; (iii) efficient network resource management, including congestion and Quality-of-Service; and (iv) end-to-end functions implemented at the network edges. This paper presents key achievements and results at the midterm of the project for each key pillar in the way to reach the final project objective. In this regard we can highlight: (i) The definition of the network requirements and architecture as well as a list of benchmarks and applications; (ii) In addition to initially planned IPs progress, BXI3 architecture has evolved to support natively Ethernet at low level, resulting in reduced complexity, with advantages in terms of cost optimization, and power consumption; (iii) The congestion characterization of target applications and proposals to reduce this congestion by the optimization of collective communication primitives, injection throttling and adaptive routing; and (iv) the low-latency high-message rate endpoint functions and their connection with new open technologies.
Thèse de Doctorat de l'Université Paris-Saclay, 2024
abstract
Abstract
Le Commissariat à l'Énergie Atomique et aux Énergies Alternatives (CEA) s'intéresse à la simulation d'écoulements fluides en régime supersonique et hypersonique dans le cadre de la rentrée atmosphérique. Pour ce faire, un code de simulation numérique dédié y est développé. Pour répondre à des contraintes fortes, ce code ne prend en entrée que des maillages hexaédriques structurés par blocs. Ce type de maillage est compliqué à générer, c'est le plus souvent réalisé à la main via l'utilisation de logiciels interactifs dédiés. Pour des géométries industrielles complexes, la génération d'un maillage est très couteuse en temps. A l'heure actuelle, la génération automatique de maillages hexaédriques est un sujet de recherche ouvert et complexe.Dans le cadre de ces travaux de thèse, nous proposons une méthode permettant de générer des maillages structurés par blocs courbes de domaines fluides autour de géométries dédiées pour les problématiques visées. Cette méthode a d'abord été prototypée dans le cadre de domaines 2D, puis étendue au cas 3D. Ici, la méthode est présentée dans le cas général, en dimension n. Elle se découpe en plusieurs étapes qui sont les suivantes.Dans un premier temps, une structure de blocs linéaire est obtenue par extrusion d'une première discrétisation de la paroi. Ces travaux sont une extension des travaux proposés par Ruiz-Girones et al.. Une fois cette structure de blocs linéaire obtenue, nous proposons deux manières distinctes de courber les blocs afin d'améliorer la représentation de la géométrie, et de limiter le lissage sur le maillage final. La première est à travers d'un processus de lissage de maillage à topologie fixe à l'aide d'un problème d'optimisation, auquel un terme de pénalité est ajouté pour aligner certaines arêtes du maillage aux interfaces. Dans notre processus, nous appliquons cette méthode de lissage à la structure de blocs pour l'aligner sur la surface du véhicule. Cette méthode étant pour l'instant trop couteuse en temps de calcul dans le cas 3D, nous proposons une seconde manière de courber les blocs, à travers une représentation à l'aide de courbes polynomiales de Béziers. Nous appliquons cette fois des opérations géométriques et locales afin d'aligner les blocs à la géométrie.Enfin, en partant du principe que les blocs sont représentés à l'aide de courbes de Bézier, nous générons un maillage final sur ces blocs courbes sous différentes contraintes. Finalement, nous évaluons la qualité des maillages générés à travers des critères purement géométriques, en étudiant l'impact des différents paramètres de notre méthode sur le maillage final. Nous évaluons également les maillages générés par la simulation d'écoulements fluides sur ces maillages, avec la comparaison à des données expérimentales, analytiques, ainsi qu'à des calculs de référence.
2023
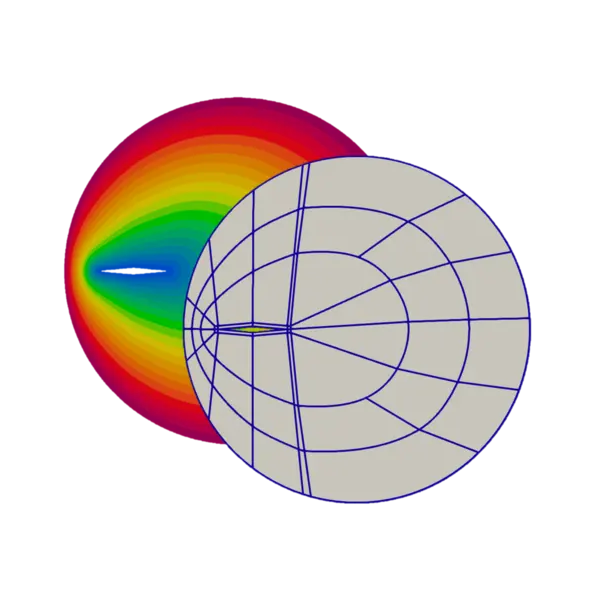
SIAM International Meshing Roundtable 2023, Springer Nature Switzerland, p. 43-63, 2023
abstract
Abstract
This paper presents Coupe, a mesh partitioning platform. It provides solutions to solve different variants of the mesh partitioning problem, mainly in the context of load-balancing parallel mesh-based applications. From partitioning weights ensuring balance to topological partitioning that minimizes communication metrics through geometric methods, Coupe offers a large panel of algorithms to fit user-specific problems. Coupe exploits shared memory parallelism, is written in Rust, and consists of an open-source library and command line tools. Experimenting with different algorithms and parameters is easy. The code is available on Github.
Euro-Par 2022 International Workshops, Glasgow, UK, August 22–26, 2022, Revised Selected Papers, Glasgow, United Kingdom, 2023
abstract

Abstract
Mesh partitioning used for load balancing in distributed numerical simulations is typically managed with tools that are good enough but not optimal. Their use scope is not explicitly dedicated to load balancing, and they cannot make use of all available information. In this paper, the mesh partitioning problem and the context for its use are precisely defined. Then, existing tools are presented, along with their characteristics and features that are missing. Finally, a new partitioning platform – the subject of my PhD thesis – is presented: its architecture, software engineering choices made along the way, and how it can be the best fit for load balancing distributed simulations. The platform is open-source and is hosted on GitHub: https://github.com/LIHPC-Computational-Geometry/coupe .
IEEE International Conference on Quantum Computing and Engineering, 2023
abstract
Abstract
Quantum computers exploit the particular behavior of quantum physical systems to solve some problems in a different way than classical computers. We are now approaching the point where quantum computing could provide real advantages over classical methods. The computational capabilities of quantum systems will soon be available in future supercomputer architectures as hardware accelerators called Quantum Processing Units (QPU). From optimizing compilers to task scheduling, the High-Performance Computing (HPC) software stack could benefit from the advantages of quantum computing. We look here at the problem of register allocation, a crucial part of modern optimizing compilers. We propose a simple proof-of-concept hybrid quantum algorithm based on QAOA to solve this problem. We implement the algorithm and integrate it directly into GCC, a well-known modern compiler. The performance of the algorithm is evaluated against the simple Chaitin-Briggs heuristic as well as GCC's register allocator. While our proposed algorithm lags behind GCC's modern heuristics, it is a good first step in the design of useful quantum algorithms for the classical HPC software stack.
Communications in Computational Physics, 2023
abstract
Abstract
The DDFV (Discrete Duality Finite Volume) method is a finite volume scheme mainly dedicated to diffusion problems, with some outstanding properties. This scheme has been found to be one of the most accurate finite volume methods for diffusion problems. In the present paper, we propose a new monotonic extension of DDFV, which can handle discontinuous tensorial diffusion coefficient. Moreover, we compare its performance to a diamond type method with an original interpolation method relying on polynomial reconstructions. Monotonicity is achieved by adapting the method of Gao et al [A finite volume element scheme with a monotonicity correction for anisotropic diffusion problems on general quadrilateral meshes] to our schemes. Such a technique does not require the positiveness of the secondary unknowns. We show that the two new methods are second-order accurate and are indeed monotonic on some challenging benchmarks as a Fokker-Planck problem.
Kinetic and Related Models, 2023
Journal of Computational Physics, p. 111721, 2023
Computational & Applied Mathematics, vol 42, 2023
abstract
Abstract
When solving numerically an elliptic problem, it is important in most applications that the scheme used preserves the positivity of the solution. When using finite volume schemes on deformed meshes, the question has been solved rather recently. Such schemes are usually (at most) second-order convergent, and non-linear. On the other hand, many high-order schemes have been proposed that do not ensure positivity of the solution. In this paper, we propose a very high-order monotonic (that is, positivity preserving) numerical method for elliptic problems in 1D. We prove that this method converges to an arbitrary order (under reasonable assumptions on the mesh) and is indeed monotonic. We also show how to handle discontinuous sources or diffusion coefficients, while keeping the order of convergence. We assess the new scheme, on several test problems, with arbitrary (regular, distorted, and random) meshes.
Abstract
Quad meshing is a very well-studied domain for many years. Although the problem can generally be considered solved, many approaches do not provide adequate inputs for Computational Fluid Dynamics (CFD) and, in our case, hypersonic flow simulations. Such simulations require very strong monitoring of cell size and direction. To our knowledge, engineers do this manually with the help of interactive software. In this work we propose an automatic algorithm to generate full quadrilateral block structured mesh for the purpose of hypersonic flow simulation. Using this approach we can handle some simulation input like the angle of attack and the boundary layer definition. We will present here 2D results of computation on a hypersonic vehicle using the meshes generated by our method.
SIAM CSE 2023 - SIAM Conference on Computational Science and Engineering, 2023
abstract
Abstract
Heterogeneous supercomputers with GPUs are one of the best candidates to build Exascale machines. However, porting scientific applications with millions of lines of code lines is challenging. Data transfers/locality and exposing enough parallelism determine the maximum achievable performance on such systems. Thus porting efforts impose developers to rewrite parts of the application which is tedious and time-consuming and does not guarantee performances in all the cases. Being able to detect which parts can be expected to deliver performance gains on GPUs is therefore a major asset for developers. Moreover, task parallel programming model is a promising alternative to expose enough parallelism while allowing asynchronous execution between CPU and GPU. OpenMP 4.5 introduces the « target » directive to offload computation on GPU in a portable way. Target constructions are considered as explicit OpenMP task in the same way as for CPU but executed on GPU. In this work, we propose a methodology to detect the most profitable loops of an application that can be ported on GPU. While we have applied the detection part on several mini applications (LULESH, miniFE, XSBench and Quicksilver), we experimented the full methodology on LULESH through MPI+OpenMP task programming model with target directives. It relies on runtime modifications to enable overlapping of data transfers and kernel execution through tasks. This work has been integrated into the MPC framework, and has been validated on distributed heterogeneous system.
52nd International Conference on Parallel Processing (ICPP 2023), 2023
abstract
Abstract
The architecture of supercomputers is evolving to expose massive parallelism. MPI and OpenMP are widely used in application codes on the largest supercomputers in the world. The community primarily focused on composing MPI with OpenMP before its version 3.0 introduced task-based programming. Recent advances in OpenMP task model and its interoperability with MPI enabled fine model composition and seamless support for asynchrony. Yet, OpenMP tasking overheads limit the gain of task-based applications over their historical loop parallelization (parallel for construct). This paper identifies the OpenMP task dependency graph discovery speed as a limiting factor in the performance of task-based applications. We study its impact on intra and inter-node performances over two benchmarks (Cholesky, HPCG) and a proxy-application (LULESH). We evaluate the performance impacts of several discovery optimizations, and introduce a persistent task dependency graph reducing overheads by a factor up to 15 at run-time. We measure 2x speedup over parallel for versions weak scaled to 16K cores, due to improved cache memory use and communication overlap, enabled by task refinement and depth-first scheduling.
IWOMP 23 - International Workshop on OpenMP, 2023
abstract
Abstract
Many-core and heterogeneous architectures now require programmers to compose multiple asynchronous programming model to fully exploit hardware capabilities. As a shared-memory parallel programming model, OpenMP has the responsibility of orchestrating the suspension and progression of asynchronous operations occurring on a compute node, such as MPI communications or CUDA/HIP streams. Yet, specifications only come with the task detach(event) API to suspend tasks until an asynchronous operation is completed, which presents a few drawbacks. In this paper, we introduce the design and implementation of an extension on the taskwait construct to suspend a task until an asynchronous event completion. It aims to reduce runtime costs induced by the current solution, and to provide a standard API to automate portable task suspension solutions. The results show twice less overheads compared to the existing task detach clause.
Abstract
High-Performance Computing (HPC) is currently facing significant challenges. The hardware pressure has become increasingly difficult to manage due to the lack of parallel abstractions in applications. As a result, parallel programs must undergo drastic evolution to effectively exploit underlying hardware parallelism. Failure to do so results in inefficient code. In this pressing environment, parallel runtimes play a critical role, and their esting becomes crucial. This paper focuses on the MPI interface and leverages the MPI binding tools to develop a multi-language test-suite for MPI. By doing so and building on previous work from the Forum’s document editors, we implement a systematic testing of MPI symbols in the context of the Parallel Computing Validation System (PCVS), which is an HPC validation platform dedicated to running and managing test-suites at scale. We first describe PCVS, then outline the process of generating the MPI API test suite, and finally, run these tests at scale. All data sets, code generators, and implementations are made available in open-source to the community. We also set up a dedicated website showcasing the results, which self-updates thanks to the Spack package manager.
ISC High Performance 2023: High Performance Computing pp 28–41, 2023
abstract
Abstract
The field of High-Performance Computing is rapidly evolving, driven by the race for computing power and the emergence of new architectures. Despite these changes, the process of launching programs has remained largely unchanged, even with the rise of hybridization and accelerators. However, there is a need to express more complex deployments for parallel applications to enable more efficient use of these machines. In this paper, we propose a transparent way to express malleability within MPI applications. This process relies on MPI process virtualization, facilitated by a dedicated privatizing compiler and a user-level scheduler. With this framework, using the MPC thread-based MPI context, we demonstrate how code can mold its resources without any software changes, opening the door to transparent MPI malleability. After detailing the implementation and associated interface, we present performance results on representative applications.
Abstract
MPI is the most widely used interface for high-performance computing (HPC) workloads. Its success lies in its embrace of libraries and ability to evolve while maintaining backward compatibility for older codes, enabling them to run on new architectures for many years. In this paper, we propose a new level of MPI compatibility: a standard Application Binary Interface (ABI). We review the history of MPI implementation ABIs, identify the constraints from the MPI standard and ISO C, and summarize recent efforts to develop a standard ABI for MPI. We provide the current proposal from the MPI Forum’s ABI working group, which has been prototyped both within MPICH and as an independent abstraction layer called Mukautuva. We also list several use cases that would benefit from the definition of an ABI while outlining the remaining constraints.
Abstract
The coupling through both drag force and volume fraction (of gas) of a kinetic equation of Vlasov type and a system of Euler or Navier–Stokes type (in which the volume fraction explicity appears) leads to the so-called thick sprays equations. Those equations are used to describe sprays (droplets or dust specks in a surrounding gas) in which the volume fraction of the disperse phase is non negligible. As for other multiphase flows systems, the issues related to the linear stability around homogeneous solutions is important for the applications. We show in this paper that this stability indeed holds for thick sprays equations, under physically reasonable assumptions. The analysis which is performed makes use of Lyapunov functionals for the linearized equations.
ACM Transactions on Mathematical Software, Volume 48, Issue 4, 2023
abstract
Abstract
Floating-point numbers represent only a subset of real numbers. As such, floating-point arithmetic introduces approximations that can compound and have a significant impact on numerical simulations. We introduce encapsulated error, a new way to estimate the numerical error of an application and provide a reference implementation, the Shaman library. Our method uses dedicated arithmetic over a type that encapsulates both the result the user would have had with the original computation and an approximation of its numerical error. We thus can measure the number of significant digits of any result or intermediate result in a simulation. We show that this approach, although simple, gives results competitive with state-of-the-art methods. It has a smaller overhead, and it is compatible with parallelism, making it suitable for the study of large-scale applications.
Abstract
The exploitation of urban-material spectral properties is of increasing importance for a broad range of applications, such as urban climate-change modeling and mitigation or specific/dangerous roof-material detection and inventory. A new spectral library dedicated to the detection of roof material was created to reflect the regional diversity of materials employed in Wallonia, Belgium. The Walloon Roof Material (WaRM) spectral library accounts for 26 roof material spectra in the spectral range 350–2500 nm. Spectra were acquired using an ASD FieldSpec3 Hi-Res spectrometer in laboratory conditions, using a spectral sampling interval of 1 nm. The analysis of the spectra shows that spectral signatures are strongly influenced by the color of the roof materials, at least in the VIS spectral range. The SWIR spectral range is in general more relevant to distinguishing the different types of material. Exceptions are the similar properties and very close spectra of several black materials, meaning that their spectral signatures are not sufficiently different to distinguish them from each other. Although building materials can vary regionally due to different available construction materials, the WaRM spectral library can certainly be used for wider applications; Wallonia has always been strongly connected to the surrounding regions and has always encountered climatic conditions similar to all of Northwest Europe.
2023
International Meshing Roundtable, 2023
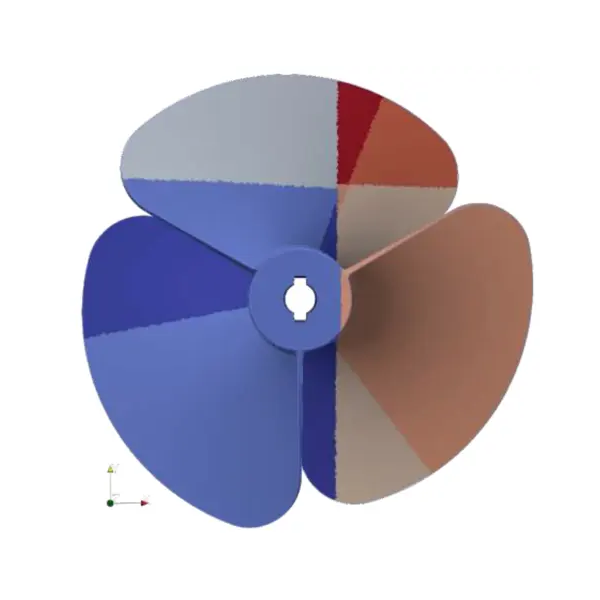
abstract
Abstract
Quad meshing is a very well-studied domain for many years. While the problem can be globally considered as solved, many approaches do not provide suitable inputs for Computational Fluid Dynamics (CFD) and in our case for supersonic flow simulations. Such simulations require a very strong control on the cell size and direction. To our knowledge, engineers ensure this control manually using interactive software. In this work we propose an automatic algorithm to generate full quadrilateral block structured mesh for the purpose of supersonic flow simulation. We handle some simulation input like the angle of attack and the boundary layer definition. Our approach generates adequate 2D meshes and is designed to be extensible in 3D.
Thèse de Doctorat de l'Université Paris-Saclay, 2023
abstract
Abstract
Cette étude s'inscrit dans le domaine de l'optimisation de performances de simulations numériques distribuées à grande échelle à base de maillages. Dans ce domaine, nous nous intéressons au bon équilibre de charge entre les unités de calcul sur lesquelles la simulation s'exécute. Pour équilibrer la charge d'une simulation à base de maillage, il faut généralement prendre en compte de la quantité de calcul nécessaire pour chaque maille, ainsi que la quantité de données qui doivent être transférées entre les unités de calcul. Les outils communément utilisés pour résoudre ce problème le solvent d'une manière, qui n'est pas forcément optimale pour une simulation donnée, car ils s'appliquent à de nombreux cas autres que l'équilibrage de charge et le partitionnement de maillage. Notre étude consiste à concevoir et implémenter un nouvel outil de partitionnement dédié aux maillages et à l'équilibrage de charge. Après une explication approfondie du contexte de l'étude, des problèmes de partitionnement ainsi que de l'état de l'art des algorithmes de partitionnement, nous montrons l'intérêt de chaîner des algorithmes pour optimiser de différentes façon une partition de maillage. Ensuite, nous étoffons cette méthode de chaînage en deux points: d'abord, en étendant l'algorithme de partitionnement de nombres VNBest pour l'équilibrage de charge où les unités de calcul sont hétérogènes, puis en spécialisant l'algorithme de partitionnement géométrique RCB, pour améliorer ses performances sur les maillages cartésiens. Nous décrivons en détails le processus de conception de notre outil de partitionnement, qui fonctionne exclusivement en mémoire partagée. Nous montrons notre outil peut obtenir des partitions avec un meilleur équilibre de charge que deux outils de partitionnement en mémoire partagée existants, Scotch et Metis. Cependant, nous ne minimisons pas aussi bien les transferts de données entre unités de calcul. Nous présentons les caractéristiques de performance des algorithmes implémentés en *multithread*.
SIAM International Meshing Roundtable, 2023
abstract
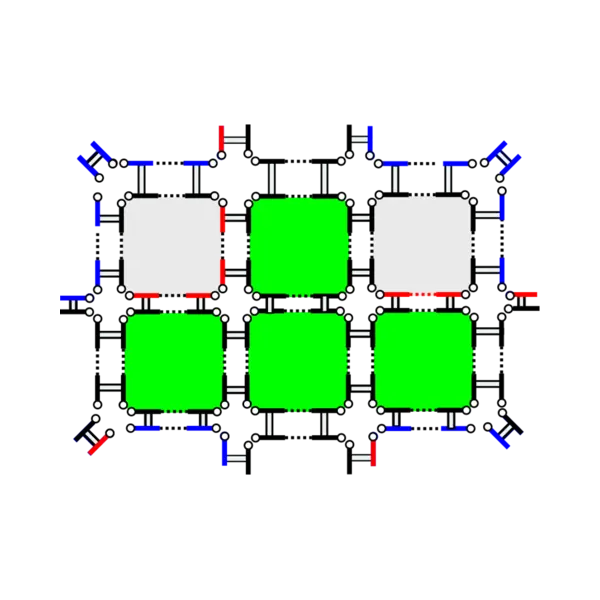
Abstract
Nowadays for real study cases, the generation of full block structured hexahedral meshes is mainly an interactive and very-time consuming process realized by highly-qualified engineers. To this purpose, they use interactive software where they handle and modify complex block structures with operations like block removal, block insertion, O-grid insertion, propagation of block splitting, propagation of meshing parameters along layers of blocks and so on. Such operations are error-prone and modifying or adding an operation is a very tedious work. In this work, we propose to formally define hexahedral block structures and main associated operations in the model of n-dimensional generalized map. This model provides topological invariant and a systematic handling of geometric data that allows us to ensure the expected robustness.
SLE '23: 16th ACM SIGPLAN International Conference on Software Language Engineering, 2023
abstract
Abstract
Software languages have pros and cons, and are usually chosen accordingly. In this context, it is common to involve different languages in the development of complex systems, each one specifically tailored for a given concern. However, these languages create de facto silos, and offer little support for interoperability with other languages, be it statically or at runtime. In this paper, we report on our experiment on extracting a relevant behavioral interface from an existing language, and using it to enable interoperability at runtime. In particular, we present a systematic approach to define the behavioral interface and we discuss the expertise required to define it. We illustrate our work on the case study of SciHook, a C++ library enabling the runtime instrumentation of scientific software in Python. We present how the proposed approach, combined with SciHook, enables interoperability between Python and a domain-specific language dedicated to numerical analysis, namely NabLab, and discuss overhead at runtime.
Thèse de Doctorat de l'Université Paris Cité, 2023
abstract
Abstract
The objective of this thesis is the development and the analysis of robust and accurate finite volume schemes for the approximation of the solution of the diffusion equation on deformed meshes with diffusion coefficient which can be anisotropic and/or discontinuous. To satisfy these properties, our schemes must preserve the positivity and achieve high-order accuracy. In this manuscript, we propose the first positivity-preserving arbitrary-order scheme for diffusion. Our approach is first to study the problem in 1D. In such a case, the positivity problem only appears for order 3 and higher. The 1D setting allows us to perform the mathematical analysis of this problem, including a proof of convergence of the scheme to an arbitrary order under a stability assumption. We then extend it to 2D at order 2, relying on well-known schemes. We study two possibilities: a DDFV-type scheme (Discrete Duality Finite Volume), which we compare with a method using polynomial reconstruction. Finally, this allows us to develop a monotonic scheme of arbitrary order on any mesh with a kappa diffusion coefficient that can be discontinuous and/or anisotropic. Improving the order is achieved through polynomial reconstruction, and monotonicity is obtained by reducing to a M-matrix structure, which gives nonlinear schemes. Each scheme is validated by numerical simulations showing the order of convergence and the positivity of the solution obtained.
Thèse de Doctorat de l'Université Paris-Saclay, 2023
abstract
Abstract
Cette thèse présente NFS-Ganesha, un serveur NFS en espace utilisateur pour le HPC, et ses évolutions depuis sa création à l'aube des années 2000 jusqu'à la période Exascale actuelle. Créé à l'origine pour des besoins opérationnels liés à l'exploitation des grands systèmes de stockage, NFS-Ganesha a été pensé pour être générique et parallélisé. L'apparition conjointe des systèmes de fichiers parallèles, donnant naissance aux architectures «data-centriques» de centre de calcul, et celle du protocole NFSv4 vont faire évoluer de NFS-Ganesha qui va devenir un serveur NFS générique capable de s'interfacer avec de nombreux backends. L'évolution de NFSv4, sous la forme de NFSv4.1 et du protocole pNFS, fera de NFS-Ganesha un standard adopté par une forte communauté open-source impliquant chercheurs et industriels. NFS-Ganesha sera utilisé pour réaliser la fonctionnalité IO-Proxy, et la création de nouveaux protocoles parallèles afférents. Impliqués dans des projets de R&D européens, NFS-Ganesha servira à implémenter la fonctionnalité de serveur éphémère afin de répondre aux exigences de l'Exascale.
7th Workshop on Performance and Scalability of Storage Systems (Per3S), 2023
SC-W '23: Proceedings of the SC '23 Workshops of The International Conference on High Performance Computing, Network, Storage, and Analysis, 2023
abstract
Abstract
HPC application developers and administrators need to understand the complex interplay between compute clusters and storage systems to make effective optimization decisions. Ad hoc investigations of this interplay based on isolated case studies can lead to conclusions that are incorrect or difficult to generalize. The I/O Trace Initiative aims to improve the scientific community’s understanding of I/O operations by building a searchable collaborative archive of I/O traces from a wide range of applications and machines, with a focus on high-performance computing and scalable AI/ML. This initiative advances the accessibility of I/O trace data by enabling users to locate and compare traces based on user-specified criteria. It also provides a visual analytics platform for in-depth analysis, paving the way for the development of advanced performance optimization techniques. By acting as a hub for trace data, the initiative fosters collaborative research by encouraging data sharing and collective learning.
Journal of Computational Physics, Volume 478, 1 April 2023, 2023
abstract
Abstract
In this paper, we propose an adaptive mesh refinement method for 2D multi-material compressible non-viscous flows in semi-Lagrangian coordinates. The mesh adaptation procedure is local and relies on a discrete metric field evaluation. The remapping method is second-order accurate and we prove its stability. We propose a multi-material treatment using two ingredients: the local remeshing is performed in a way that reduces as much as possible the creation of mixed cells and an interface reconstruction method that can be used to avoid the diffusion of the material interfaces. The obtained method is almost Lagrangian and can be implemented in a parallel framework. We provide some numerical tests which attest the validity of the method and its robustness.
ESAIM M2AN Volume 57, Number 2, March-April 2023, 2023
abstract
Abstract
We construct an original framework based on convex analysis to prove the existence and uniqueness of a solution to a class of implicit numerical schemes. We propose an application of this general framework in the case of a new non linear implicit scheme for the 1D Lagrangian gas dynamics equations. We provide numerical illustrations that corroborate our proof of unconditional stability for this non linear implicit scheme.
2022
Journal of Computational Physics, p. 110859, 2022
Euro-Par 2022: Parallel Processing - 28th International Conference on Parallel and Distributed Computing, Glasgow, UK, August 22-26, 2022, Proceedings, Springer, p. 85-99, 2022
Proceedings of SBAC-PAD 2022, IEEE, 2022
abstract
Abstract
HPC systems have experienced significant growth over the past years, with modern machines having hundreds of thousands of nodes. Message Passing Interface (MPI) is the de facto standard for distributed computing on these architectures. On the MPI critical path, the message-matching process is one of the most time-consuming operations. In this process, searching for a specific request in a message queue represents a significant part of the communication latency. So far, no miracle algorithm performs well in all cases. This paper explores potential matching specializations thanks to hints introduced in the latest MPI 4.0 standard. We propose a hash-table-based algorithm that performs constant time message-matching for no wildcard requests. This approach is suitable for intensive point-to-point communication phases in many applications (more than 50% of CORAL benchmarks). We demonstrate that our approach can improve the overall execution time of real HPC applications by up to 25%. Also, we analyze the limitations of our method and propose a strategy for identifying the most suitable algorithm for a given application. Indeed, we apply machine learning techniques for classifying applications depending on their message pattern characteristics.
Concurr. Comput. Pract. Exp., 2022
abstract
Abstract
By allowing computation/communication overlap, MPI nonblocking collectives (NBC) are supposed to improve application scalability and performance. However, it is known that to actually get overlap, the MPI library has to implement progression mechanisms in software or rely on the network hardware. These mechanisms may be present or not, adequate or perfectible, they may have an impact on communication performance or may interfere with computation by stealing CPU cycles. From a user point of view, assessing and understanding the behavior of an MPI library concerning computation/communication overlap is difficult. In this article, we propose a methodology to assess the computation/communication overlap of NBC. We propose new metrics to measure how much communication and computation do overlap, and to evaluate how they interfere with each other. We integrate these metrics into a complete methodology. We compare our methodology with state of the art metrics and benchmarks, and show that ours provides more meaningful informations. We perform experiments on a large panel of MPI implementations and network hardware and show when and why overlap is efficient, nonexistent or even degrades performance.
Parallel Comput., p. 102860, 2022
Abstract
The ablation of a vehicle during atmospheric reentry leads to a degradation of its surface condition. Ablated wall interacts with the boundary layer that develops around the object. The deformation can be seen as a ripple or a roughness pattern with different characteristic amplitudes and wavelenghts. The effect of this defect on the flow is taken into account either by means of modelizations or by direct simulation by applying the strains to the mesh. Mesh adaptation techniques can be used in order to take into account wall deformations during a simulation. The principle is to start from an initially smooth mesh, to apply a strain law, then to use regularization and refinement methods. The meshes will be adapted for use in a parallel CFD Navier-Stokes code. A refinement of the mesh close to the wall is required to correctly capture the boundary layer [2], but also to accuratly represent the geometry of the wall deformation. For the numerical methods used, a constraint of orthogonality is added to the mesh impining on the wall. The developments are for the moments, carried out in an independent external tool. The regularization methods are compared on results of simulations with different meshes. The method can be easily coupled with a CFD code and can be extended to 3D geometries.
Parallel Comput., p. 102859, 2022
22nd IEEE International Symposium on Cluster, Cloud and Internet Computing, CCGrid 2022, Taormina, Italy, May 16-19, 2022, IEEE, p. 736-746, 2022
abstract
Abstract
Overlapping communications with computation is an efficient way to amortize the cost of communications of an HPC application. To do so, it is possible to utilize MPI nonblocking primitives so that communications run in back-ground alongside computation. However, these mechanisms rely on communications actually making progress in the background, which may not be true for all MPI libraries. Some MPI libraries leverage a core dedicated to communications to ensure communication progression. However, taking a core away from the application for such purpose may have a negative impact on the overall execution time. It may be difficult to know when such dedicated core is actually helpful. In this paper, we propose a model for the performance of applications using MPI nonblocking primitives running on top of an MPI library with a dedicated core for communications. This model is used to understand the compromise between computation slowdown due to the communication core not being available for computation, and the communication speed-up thanks to the dedicated core; evaluate whether nonblocking communication is actually obtaining the expected performance in the context of the given application; predict the performance of a given application if ran with a dedicated core. We describe the performance model and evaluate it on different applications. We compare the predictions of the model with actual executions.
EuroMPI/USA'22: 29th European MPI Users' Group Meeting, Chattanooga, TN, USA, September 26 - 28, 2022, ACM, p. 27-36, 2022

Abstract
Polycube-maps are used as base-complexes in various fields of computational geometry, including the generation of regular all-hexahedral meshes free of internal singularities. However, the strict alignment constraints behind polycube-based methods make their computation challenging for CAD models used in numerical simulation via finite element method (FEM). We propose a novel approach based on an evolutionary algorithm to robustly compute polycube-maps in this context. We address the labelling problem, which aims to precompute polycube alignment by assigning one of the base axes to each boundary face on the input. Previous research has described ways to initialize and improve a labelling via greedy local fixes. However, such algorithms lack robustness and often converge to inaccurate solutions for complex geometries. Our proposed framework alleviates this issue by embedding labelling operations in an evolutionary heuristic, defining fitness, crossover, and mutations in the context of labelling optimization. We evaluate our method on a thousand smooth and CAD meshes, showing Evocube converges to accurate labellings on a wide range of shapes. The limitations of our method are also discussed thoroughly.

Abstract
An important part of recent advances in hexahedral meshing focuses on the deformation of a domain into a polycube; the polycube deformed by the inverse map fills the domain with a hexahedral mesh. These methods are appreciated because they generate highly regular meshes. In this paper we address a robustness issue that systematically occurs when a coarse mesh is desired: algorithms produce deformations that are not one-to-one, leading to collapse of large portions of the model when trying to apply the (undefined) inverse map. The origin of the problem is that the deformation requires to perform a mixed integer optimization, where the difficulty to enforce the integer constraints is directly tied to the expected coarseness. Our solution is to introduce sanity constraints preventing the loss of bijectivity due to the integer constraints.
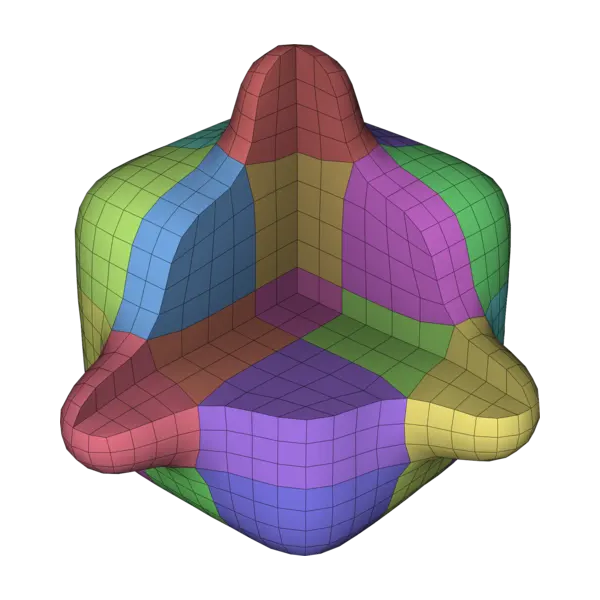
Abstract
In this article, we provide a detailed survey of techniques for hexahedral mesh generation. We cover the whole spectrum of alternative approaches to mesh generation, as well as post-processing algorithms for connectivity editing and mesh optimization. For each technique, we highlight capabilities and limitations, also pointing out the associated unsolved challenges. Recent relaxed approaches, aiming to generate not pure-hex but hex-dominant meshes, are also discussed. The required background, pertaining to geometrical as well as combinatorial aspects, is introduced along the way.

Abstract
Abstract HexMe consists of 189 tetrahedral meshes with tagged features and a workflow to generate them. The primary purpose of HexMe meshes is to enable consistent and practically meaningful evaluation of hexahedral meshing algorithms and related techniques, specifically regarding the correct meshing of specified feature points, curves, and surfaces. The tetrahedral meshes have been generated with Gmsh, starting from 63 computer-aided design (CAD) models from various databases. To highlight and label the diverse and challenging aspects of hexahedral mesh generation, the CAD models are classified into three categories: simple, nasty, and industrial. For each CAD model, we provide three kinds of tetrahedral meshes (uniform, curvature-adapted, and box-embedded). The mesh generation pipeline is defined with the help of Snakemake, a modern workflow management system, which allows us to specify a fully automated, extensible, and sustainable workflow. It is possible to download the whole dataset or select individual meshes by browsing the online catalog. The HexMe dataset is built with evolution in mind and prepared for future developments. A public GitHub repository hosts the HexMe workflow, where external contributions and future releases are possible and encouraged. We demonstrate the value of HexMe by exploring the robustness limitations of state-of-the-art frame-field-based hexahedral meshing algorithm. Only for 19 of 189 tagged tetrahedral inputs all feature entities are meshed correctly, while the average success rates are 70.9% / 48.5% / 34.6% for feature points/curves/surfaces.
IWOMP 2022 - 18th International Workshop on OpenMP, p. 1-14, 2022
abstract
Abstract
Heterogeneous supercomputers are widespread over HPC systems and programming efficient applications on these architectures is a challenge. Task-based programming models are a promising way to tackle this challenge. Since OpenMP 4.0 and 4.5, the target directives enable to offload pieces of code to GPUs and to express it as tasks with dependencies. Therefore, heterogeneous machines can be programmed using MPI+OpenMP(task+target) to exhibit a very high level of concurrent asynchronous operations for which data transfers, kernel executions, communications and CPU computations can be overlapped. Hence, it is possible to suspend tasks performing these asynchronous operations on the CPUs and to overlap their completion with another task execution. Suspended tasks can resume once the associated asynchronous event is completed in an opportunistic way at every scheduling point. We have integrated this feature into the MPC framework and validated it on a AXPY microbenchmark and evaluated on a MPI+OpenMP(tasks) implementation of the LULESH proxy applications. The results show that we are able to improve asynchronism and the overall HPC performance, allowing applications to benefit from asynchronous execution on heterogeneous machines.
Euro-Par 2022: Parallel Processing - 28th International Conference on Parallel and Distributed Computing, Glasgow, UK, August 22-26, 2022, Proceedings, Springer, p. 136–151, 2022
Physical Review E, APS, p. 27269, 2022
Communications in Computational Physics, GLOBAL SCIENCE PRESS Office B, 9/F, Kings Wing Plaza2, No. 1 On Kwan St..., p. 398-448, 2022
CEA, LIHPC Computational Geometry group, 2022
ECCOMAS Congress 2022 - 8th European Congress on Computational Methods in Applied Sciences and Engineering, 2022
2022
p. 182-196, 2022
IEEE Transactions on Emerging Topics in Computing, p. 1-10, 2022
p. 127-127, 2022
Mesh Generation and Adaptation: Cutting-Edge Techniques, Springer International Publishing, p. 69-94, 2022
abstract
Abstract
In this chapter, we deal with the problem of mesh conversion for coupling lagrangian and eulerian simulation codes. More specifically, we focus on hexahedral meshes, which are known as pretty difficult to generate and handle. Starting from an eulerian hexahedral mesh, i.e. a hexahedral mesh where each cell contains several materials, we provide a full-automatic process that generates a lagrangian hexahedral mesh, i.e. a hexahedral mesh where each cell contains a single material. This process is simulation-driven in the meaning that the we guarantee that the generated mesh can be used by a simulation code (minimal quality for individual cells), and we try and preserve the volume and location of each material as best as possible. In other words, the obtained lagrangian mesh fits the input eulerian mesh with high-fidelity. To do it, we interleave several advanced meshing treatments--mesh smoothing, mesh refinement, sheet insertion, discrete material reconstruction, discrepancy computation, in a fully integrated pipeline. Our solution is evaluated on 2D and 3D examples representative of CFD simulation (Computational Fluid Dynamics).
Habilitation à Diriger les Recherches en Mathématiques Appliquées, Sorbonne Université, 2021. ⟨tel-03572029⟩, 2022
Thèse de Doctorat de l'Université de Paris-Saclay, 2022
abstract
Abstract
Les codes de simulation numérique reposant sur des méthodes de type éléments et volumes finis requièrent de discrétiser le domaine étudié – par exemple une pièce mécanique telle qu’un moteur, une aile d’avion, une turbine, etc. – à l’aide d’un maillage. En dimension 3, un maillage est un ensemble composé d’éléments volumique simples, le plus souvent des tétraèdres ou des hexaèdres, qui partitionnent le domaine d’étude. Le choix de tétraèdres ou d’hexaèdres est principalement dicté par l’application (interaction fluide-structure, hydrodynamique, etc.). Si la génération automatique de maillages tétraédriques est un processus relativement maîtrisé aujourd’hui, générer des maillages hexaédriques est toujours un problème ouvert. Ceci est problématique pour les applications qui justement nécessitent impérativement des maillages hexaédriques puisque leur génération se fait de façon semi-automatique, ce qui peut prendre plusieurs semaines à plusieurs mois de temps ingénieur ! Alors que le temps consacré au processus de simulation numérique à proprement parler tend à diminuer du fait de la puissance des machines utilisées, le goulot d’étranglement est désormais dans la préparation des données, à savoir obtenir un modèle de CAO adapté au calcul, puis en générer un maillage.C’est dans ce contexte que s’inscrit la thèse proposée en suivant une approche hybride mêlant :1. Le développement d’algorithmes (semi)-automatiques pour générer et modifier des maillages hexaédriques structurés par blocs ;2. La mise en place d’un logiciel graphique interactif dédié à la manipulation de structures de blocs. Les mécanismes d’interaction seront en outre utilisés pour guider les algorithmes dans leurs prises de décision, que ce soit à l’initialisation (critères à apposer sur des entités particulières de CAO) ou en cours d’algorithme (décision entre plusieurs options sur lesquelles l’algorithme ne peut se prononcer seul).L’objectif de cette thèse n’est donc pas de fournir une solution automatique universelle, ce qui semble inatteignable actuellement, mais plutôt de réduire le temps ingénieur consacré à la génération du maillage en fournissant des outils plus adaptés. Dans cette optique, nous proposons de placer l’étude dans le prolongement de [LED10, KOW12, GAO15, GAO17], où est considéré le problème de simplification et d’enrichissement de maillages hexaédriques par insertion et suppression de couches de mailles. Dans tous ces travaux, les algorithmes proposés sont des algorithmes simples de type « glouton » où le maillage est modifié pas à pas pour converger vers une solution finale Ef : A chaque étape Ei, on fait l’hypothèse que la « meilleure » solution Ef sera obtenue en faisant le choix « optimal » pour Ei. Or en recherche opérationnelle, une telle approche est connue comme perfectible dès lors que le problème d’optimisation traité est non linéaire. L’idée est donc d’utiliser des approches usuelles en recherche opérationnelle et plus spécifiquement des systèmes multi-agents, couplées à des outils interactifs, pour permettre la génération de structures de blocs sur des CA0 complexes.
Thèse de Doctorat de l'Université de Bordeaux, 2022
abstract
Abstract
De nos jours, MPI est de facto le standard pour la programmation à mémoire distribuée pour les supercalculateurs. Les communications non bloquantes sont un des modèles proposés par le standard MPI. Ces opérations peuvent être utilisées pour recouvrir les communications avec du calcul (ou d’autres communications) afin d’amortir leurs coûts. Cependant, pour être utilisées efficacement, ces opérations nécessitent une progression asynchrone pouvant régulièrement utiliser un montant non négligeable de ressources de calcul (particulièrement les collectives non bloquantes). De plus, partager les ressources de calcul avec l’application peut provoquer un ralentissement global. Les mécanismes utilisés pour cette progression asynchrone parviennent difficilement à concilier un bon recouvrement en gardant un impact minimal sur l’application, ce qui raréfie leur utilisation. Afin de résoudre ces différents problèmes, nous avons suivi plusieurs étapes. Premièrement, nous proposons une étude approfondie de la progression asynchrone dans les implémentations MPI, en utilisant de nouvelles métriques se concentrant sur l’évaluation des mécanismes de progression et de leur impact sur le système global. Après avoir exposé les faiblesses de ces implémentations MPI, nous proposons une nouvelle solution pour la progression des collectives non bloquantes en utilisant des coeurs dédiés combinés à des algorithmes de collectives basés sur des évènements. Nous avons mesuré l’efficacité de cette solution en utilisant nos métriques, pour nous comparer avec les implémentations MPI étudiées dans la première étape. Enfin, nous avons développé un modèle permettant de prédire le gain potentiel et le surcout induit par l’utilisation d’opérations non bloquantes avec des coeurs dédiés. Ce modèle peut être utilisé pour évaluer l’utilité de transformer une application basée sur des opérations bloquantes en opérations non bloquantes pour bénéficier du recouvrement. Nous évaluons ce modèle sur plusieurs benchmarks.
Computing in Science & Engineering ( Volume: 24, Issue: 4, 01 July-Aug. 2022), 2022
abstract
Abstract
Scientific codes are complex software systems. Their engineering involves various stakeholders using various computer languages for defining artifacts at different abstraction levels and for different purposes. In this article, we review the overall processes leading to the development of scientific software, and discuss the role of computer languages in the definition of the different artifacts. We provide guidelines to make informed decisions when the time comes to choose a computer language to develop scientific software.
EuroVis 2019 - 21th EG/VGTC Conference on Visualization, 2022
abstract
Abstract
With the constant increase in compute power of supercomputers, high performance computing simulations are producing higher fidelity results and possibly massive amounts of data. To keep visualization of such results interactive, existing techniques such as Adaptive Mesh Refinement (AMR) can be of use. In particular, Tree-Based AMR methods (TB-AMR) are widespread in simulations and are becoming more present in general purpose visualization pipelines such as VTK. In this work, we show how TB-AMR data structures could lead to more efficient exploration of massive data sets in the Exascale era. We discuss how algorithms (filters) should be designed to take advantage of tree-like data structures for both data filtering or rendering. By introducing controlled hierarchical data reduction we greatly reduce the processing time for existing algorithms, sometimes with no visual impact, and drastically decrease exploration time for analysts. Also thanks to the techniques and implementations we propose, visualization of very large data is made possible on very constrained resources. These ideas are illustrated on million to billion-scale native TB-AMR or resampled meshes, with the HyperTreeGrid object and associated filters we have recently optimized and made available in the Visualisation Toolkit (VTK) for use by the scientific community.
Zenodo, 2022
abstract
Abstract
This document feeds research and development priorities devel-oped by the European HPC ecosystem into EuroHPC’s Research and Innovation Advisory Group with an aim to define the HPC Technology research Work Programme and the calls for proposals included in it and to be launched from 2023 to 2026. This SRA also describes the major trends in the deployment of HPC and HPDA methods and systems, driven by economic and societal needs in Europe, taking into account the changes ex-pected in the technologies and architectures of the expanding underlying IT infrastructure. The goal is to draw a complete pic-ture of the state of the art and the challenges for the next three to four years rather than to focus on specific technologies, implementations or solutions.
2021
Tools for High Performance Computing 2018 / 2019, Springer International Publishing, p. 151-168, 2021
abstract
Abstract
The backtrace is one of the most common operations done by profiling and debugging tools. It consists in determining the nesting of functions leading to the current execution state. Frameworks and standard libraries provide facilities enabling this operation, however, it generally incurs both computational and memory costs. Indeed, walking the stack up and then possibly resolving functions pointers (to function names) before storing them can lead to non-negligible costs. In this paper, we propose to explore a means of extracting optimized backtraces with an O(1) storage size by defining the notion of stack tags. We define a new data-structure that we called a hashed-trie used to encode stack traces at runtime through chained hashing. Our process called stack-tagging is implemented in a GCC plugin, enabling its use of C and C++ application. A library enabling the decoding of stack locators though both static and brute-force analysis is also presented. This work introduces a new manner of capturing execution state which greatly simplifies both extraction and storage which are important issues in parallel profiling.
Abstract
Heterogeneous supercomputers are now considered the most valuable solution to reach the Exascale. Nowadays, we can frequently observe that compute nodes are composed of more than one GPU accelerator. Programming such architectures efficiently is challenging. MPI is the defacto standard for distributed computing. CUDAaware libraries were introduced to ease GPU inter-nodes communications. However, they induce some overhead that can degrade overall performances. MPI 4.0 Specification draft introduces the MPI Sessions model which offers the ability to initialize specific resources for a specific component of the application. In this paper, we present a way to reduce the overhead induced by CUDA-aware libraries with a solution inspired by MPI Sessions. In this way, we minimize the overhead induced by GPUs in an MPI context and allow to improve CPU + GPU programs efficiency. We evaluate our approach on various micro-benchmarks and some proxy applications like Lulesh, MiniFE, Quicksilver, and Cloverleaf. We demonstrate how this approach can provide up to a 7x speedup compared to the standard MPI model.
Proceedings of Cluster 2021, 2021
Proceedings of EuroPar 2021, 2021
Workshop on Exascale MPI, ExaMPI\@SC 2021, St. Louis, MO, USA, November 14, 2021, IEEE, p. 9-17, 2021
IWOMP 2021 - 17th International Workshop on OpenMP, p. 1-15, 2021-09
2021 IEEE 28th Symposium on Computer Arithmetic (ARITH), p. 9-16, 2021-06
Physical Review E, 2021-11
INTERNATIONAL JOURNAL OF PARALLEL PROGRAMMING, SPRINGER/PLENUM PUBLISHERS, p. 81-103, 2021
abstract
Abstract
Many applications of physics modeling use regular meshes on which computations of highly variable cost over time can occur. Distributing the underlying cells over manycore architectures is a critical load balancing step that should be performed the less frequently possible. Graph partitioning tools are known to be very effective for such problems, but they exhibit scalability problems as the number of cores and the number of cells increase. We introduce a dynamic task scheduling and mesh partitioning approach inspired by physical particle interactions. Our method virtually moves cores over a 2D/3D mesh of tasks and uses a Voronoi domain decomposition to balance workload. Displacements of cores are the result of force computations using a carefully chosen pair potential. We evaluate our method against graph partitioning tools and existing task schedulers with a representative physical application, and demonstrate the relevance of our approach.
Partie Méthodes numériques de la monographie, collection e-den, 2021
2021
abstract
Abstract
Methane (CH4) is one of the most contributing anthropogenic greenhouse gases (GHGs) in terms of global warming. Industry is one of the largest anthropogenic sources of methane, which are currently only roughly estimated. New satellite hyperspectral imagers, such as PRISMA, open up daily temporal monitoring of industrial methane sources at a spatial resolution of 30 m. Here, we developed the Characterization of Effluents Leakages in Industrial Environment (CELINE) code to inverse images of the Korpezhe industrial site. In this code, the in-Scene Background Radiance (ISBR) method was combined with a standard Optimal Estimation (OE) approach. The ISBR-OE method avoids the use of a complete and time-consuming radiative transfer model. The ISBR-OEM developed here overcomes the underestimation issues of the linear method (LM) used in the literature for high concentration plumes and controls a posteriori uncertainty. For the Korpezhe site, using the ISBR-OEM instead of the LM -retrieved CH4 concentration map led to a bias correction on CH4 mass from 4 to 16% depending on the source strength. The most important CH4 source has an estimated flow rate ranging from 0.36 ± 0.3 kg·s−1 to 4 ± 1.76 kg·s−1 on nine dates. These local and variable sources contribute to the CH4 budget and can better constrain climate change models.
IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing ( Volume: 14), 2021
abstract
Abstract
Reflectance spectroscopy is a widely used technique for mineral identification and characterization. Since modern airborne and satellite-borne sensors yield an increasing number of hyperspectral data, it is crucial to develop unsupervised methods to retrieve relevant spectral features from reflectance spectra. Spectral deconvolution aims to decompose a reflectance spectrum as a sum of a continuum modeling its overall shape and some absorption features. We present a flexible and automatic method able to deal with various minerals. The approach is based on a physical model and allows us to include noise statistics. It consists of three successive steps: first, continuum pre-estimation based on nonlinear least-squares; second, pre-estimation of absorption features using a greedy algorithm; third, refinement of the continuum and absorption estimates. The procedure is first validated on synthetic spectra, including a sensitivity study to instrumental noise and a comparison to other approaches. Then, it is tested on various laboratory spectra. In most cases, absorption positions are recovered with an accuracy lower than 5 nm, enabling mineral identification. Finally, the proposed method is assessed using hyperspectral images of quarries acquired during a dedicated airborne campaign. Minerals such as calcite and gypsum are accurately identified based on their diagnostic absorption features, including when they are in a mixture. Small changes in the shape of the kaolinite doublet are also detected and could be related to crystallinity or mixtures with other minerals such as gibbsite. The potential of the method to produce mineral maps is also demonstrated.
Proceedings Volume 11727, Algorithms, Technologies, and Applications for Multispectral and Hyperspectral Imaging XXVII, 2021
abstract
Abstract
We present a fuzzy logic approach allowing the identification of minerals from re ectance spectra acquired by hyperspectral sensors in the VNIR and SWIR ranges. The fuzzy logic system is based on a human reasoning. It compares the positions of the main and secondary absorptions of the unknown spectrum (spectral characteristics estimated beforehand) with those of a reference database (derived from mineralogical knowledge). The proposed solution is first evaluated on laboratory spectra. It is then applied to airborne HySpex and satellite-borne PRISMA images acquired during a dedicated campaign over two quarries in France. This demonstrates the relevance of the method to automatically identify minerals in different mineralogical contexts and in the presence of mixtures.
EARSeL Joint Workshop - Earth Observation for Sustainable Cities and CommunitiesAt: Liège, Belgium, 2021
abstract
Abstract
Roof materials can be a significant source of pollution for the environment and can have negative health effects. Analyses of runoff water revealed high levels of metal traces but also polycyclic aromatic hydrocarbons and phthalates. This contamination would result from corrosion and alteration of roof materials. Similarly, the alteration or combustion of asbestos contained in certain types of roofs may allow the emission and dispersion of asbestos fibres into the environment. Therefore, acquiring information on roof materials is of great interest to decrease runoff water pollution, and to improve air and environmental quality around our homes. To this end, remote sensing is a particularly relevant tool since it allows semi-automatic mapping of roof materials using multispectral or hyperspectral data. The CASMATTELE project aims to develop a semi-automatic identification tool of roofing materials over the Liege area using remote-sensing and machine learning for public authorities.
Computer (Volume: 54, Issue: 12, December 2021), 2021
abstract
Abstract
We investigate the different levels of abstraction, linked to the diverse artifacts of the scientific software development process, that a software language can propose and the validation and verification facilities associated with the corresponding level of abstraction the language can provide to the user.
Proceedings of the 14th ACM SIGPLAN International Conference on Software Language Engineering, p. 2-15, 2021
abstract
Abstract
Runtime monitoring and logging are fundamental techniques for analyzing and supervising the behavior of computer programs. However, supporting these techniques for a given language induces significant development costs that can hold language engineers back from providing adequate logging and monitoring tooling for new domain-specific modeling languages. Moreover, runtime monitoring and logging are generally considered as two different techniques: they are thus implemented separately which makes users prone to overlooking their potentially beneficial mutual interactions. We propose a language-agnostic, unifying framework for runtime monitoring and logging and demonstrate how it can be used to define loggers, runtime monitors and combinations of the two, aka. moniloggers. We provide an implementation of the framework that can be used with Java-based executable languages, and evaluate it on 2 implementations of the NabLab interpreter, leveraging in turn the instrumentation facilities offered by Truffle, and those offered by AspectJ.
Abstract
Dealing with complexity is an important challenge in software and systems engineering. In particular, designing such systems requires expertise in various heterogeneous domains. Model-Driven Engineering (MDE) is a development paradigm to cope with this complexity through the conception and use of Domain Specific Languages (DSLs). A DSL captures all the concepts required to solve a set of problems belonging to a particular domain. DSLs are geared toward domain experts without requiring experience with programming languages. Using DSLs, domain experts are able to model parts of a system using only concepts of their domain of expertise. A particular category of DSLs, Executable DSLs (xDSLs), go further as they enable, through a provided execution semantics, the definition of dynamic models, which in turn enables early dynamic Verification and Validation (V&V) activities on these models. All xDSLs share a common need for an ecosystem of tools to create, manipulate, and analyze models. But xDSLs come in many shapes and forms, as each is tailored to aparticular domain, both syntactically and semantically. Thus, for each new xDSL, tools must be developed anew, or existing tools adapted. This is a tedious and error-prone task that prompted advances in the field, enabling core and advanced V&V activities for xDSLs in a unifying way through well-defined metaprogramming approaches and generic tools leveraging them. Yet, important aspects of xDSLs and V&V activities stand to benefit from dedicated metaprogramming approaches and generic tooling, respectively. On one hand, no metaprogramming approach currently allows to define the interactions between the models conforming to an xDSL and their environment. On another hand, features at the heart of important V&V activities such as testing and debugging remain challenging to offer in a generic way. In this thesis, we provide solutions to this problem for a set of tools dedicated to offline and online analysis for xDSLs. This comes under the form of three distinct contributions. First, we provide a new metaprogramming approach to extend the definition of xDSLs to incorporate a clear definition of the possible interactions between conforming models and their environment. Second, we leverage the extended foundations for the definition of xDSLs offered by our metaprogramming approach to provide generic support for offline and online analysis for a broader scope of xDSLs, under the form of trace comprehension operators and runtime monitoring, respectively. Finally, we leverage the contributions of this thesis to provide an advanced generic modeling environment. We provide implementation details of the various tools derived from our contributions that constitute this modeling environment and illustrate how they interact with one another in different V&V scenarios. For instance, we show how they can be combined to enable the definition of test scenarios and oracles for models of reactive systems from execution traces collected during an interactive debugging session. In the context of MDE, where the diversity of xDSLs hampers reuse of tools from one language to another, this thesis aims to extend the foundations upon which generic tools can be defined, and to build upon these extended foundations to provide generic support for defining features of V&V activities such as testing and debugging. This results in an advanced and improved framework in term of V&V for xDSLs, compared to the state of the art.
SIAM Journal on Scientific Computing, 2021
abstract
Abstract
The sensitivity equation method aims at estimating the derivative of the solution of partial differential equations with respect to a parameter of interest. The objective of this work is to investigate the ability of an isogeometric discontinuous Galerkin (DG) method to evaluate accurately sensitivities with respect to shape parameters originating from computer-aided design (CAD) in the context of compressible aerodynamics. The isogeometric DG method relies on nonuniform rational B-spline representations, which allows us to define a high-order numerical scheme for Euler/Navier--Stokes equations, fully consistent with CAD geometries. We detail how this formulation can be exploited to construct an efficient and accurate approach to evaluate shape sensitivities. A particular attention is paid to the treatment of boundary conditions for sensitivities, which are more tedious in the case of geometrical parameters. The proposed methodology is first verified on a test-case with an analytical solution and then applied to two more demanding problems that concern the inviscid flow around an airfoil with its camber as a shape parameter and the unsteady viscous flow around a three-element airfoil with the positions of slat and flap as parameters.
CHEOPS '21: Proceedings of the Workshop on Challenges and Opportunities of Efficient and Performant Storage Systems, p. 1-9, 2021
abstract
Abstract
The emergence of Exascale machines in HPC will have the foreseen consequence of putting more pressure on the storage systems in place, not only in terms of capacity but also bandwidth and latency. With limited budget we cannot imagine using only storage class memory, which leads to the use of a heterogeneous tiered storage hierarchy. In order to make the most efficient use of the high performance tier in this storage hierarchy, we need to be able to place user data on the right tier and at the right time. In this paper, we assume a 2-tier storage hierarchy with a high performance tier and a high capacity archival tier. Files are placed on the high performance tier at creation time and moved to capacity tier once their lifetime expires (that is once they are no more accessed). The main contribution of this paper lies in the design of a file lifetime prediction model solely based on its path based on the use of Convolutional Neural Network. Results show that our solution strikes a good trade-off between accuracy and under-estimation. Compared to previous work, our model made it possible to reach an accuracy close to previous work (around 98.60% compared to 98.84%) while reducing the underestimations by almost 10x to reach 2.21% (compared to 21.86%). The reduction in underestimations is crucial as it avoids misplacing files in the capacity tier while they are still in use.
Simulation Tools and Techniques, Springer International Publishing, p. 796-810, 2021
abstract
Abstract
In the High Performance Computing field (HPC), metadata server cluster is a critical aspect of a storage system performance and with object storage growth, systems must now be able to distribute metadata across servers thanks to distributed metadata servers. Storage systems reach better performances if the workload remains balanced over time. Indeed, an unbalanced distribution can lead to frequent requests to a subset of servers while other servers are completely idle. To avoid this issue, different metadata distribution methods exist and each one has its best use cases. Moreover, each system has different usages and different workloads, which means that one distribution method could fit to a specific kind of storage system and not to another one. To this end, we propose a tool to evaluate metadata distribution methods with different workloads. In this paper, we describe this tool and we use it to compare state-of-the-art methods and one method we developed. We also show how outputs generated by our tool enable us to deduce distribution weakness and chose the most adapted method.
2020
J. Comput. Phys., p. 109247, 2020
2020 IEEE International Parallel and Distributed Processing Symposium Workshops, IPDPSW 2020, New Orleans, LA, USA, May 18-22, 2020, IEEE, p. 958-966, 2020
OpenMP: Portable Multi-Level Parallelism on Modern Systems - 16th International Workshop on OpenMP, IWOMP 2020, Austin, TX, USA, September 22-24, 2020, Proceedings, Springer, p. 313-327, 2020
EuroMPI/USA '20: 27th European MPI Users' Group Meeting, Virtual Meeting, Austin, TX, USA, September 21-24, 2020, ACM, p. 51-60, 2020
2020 IEEE/ACM International Workshop on Runtime and Operating Systems for Supercomputers, ROSS\@SC 2020, Atlanta, GA, USA, November 13, 2020, IEEE, p. 1-11, 2020
4th IEEE/ACM International Workshop on Software Correctness for HPC Applications, Correctness\@SC 2020, Atlanta, GA, USA, November 11, 2020, IEEE, p. 31-39, 2020
High Performance Computing - ISC High Performance 2020 International Workshops, Frankfurt, Germany, June 21-25, 2020, Revised Selected Papers, Springer, p. 43-54, 2020
Journal of Computational Physics, p. 109405, 2020
Journal of Computational and Theoretical Transport, p. 162-194, 2020
2020 Proceedings of the SIAM Workshop on Combinatorial Scientific Computing, p. 85-95, 2020
abstract
Abstract
Running numerical simulations on HPC architectures requires distributing data to be processed over the various available processing units. This task is usually done by partitioning tools, whose primary goal is to balance the workload while minimizing inter-process communication. However, they do not take the memory load and memory capacity of the processing units into account. As this can lead to memory overflow, we propose a new approach to address mesh partitioning by including ghost cells in the memory usage and by considering memory capacity as a strong constraint to abide. We model the problem using a bipartite graph and present a new greedy algorithm that aims at producing a partition according to the memory capacity. This algorithm focuses on memory consumption, and we use it in a multi-level approach to improving the quality of the returned solutions during the refinement phase. The experimental results obtained from our benchmarks show that our approach can yield solutions respecting memory constraints for instances where traditional partitioning tools fail.
Journal of Computational Physics, p. 109275, 2020
COMPUTER PHYSICS COMMUNICATIONS, ELSEVIER, 2020
abstract
Abstract
Accurate simulations of metal under heavy shocks, leading to fragmentation and ejection of particles, cannot be achieved by simply hydrodynamic models and require to be performed at atomic scale using molecular dynamics methods. In order to cope with billions of particles exposed to short range interactions, such molecular dynamics methods need to be highly optimized over massively parallel supercomputers. In this paper, we propose to leverage Adaptive Mesh Refinement techniques to improve efficiency of molecular dynamics code on highly heterogeneous particle configurations. We introduce a series of techniques that optimize the force computation loop using multi-threading and vectorization-friendly data structures. Our design is guided by the need for load balancing and adaptivity raised by highly dynamic particle sets. We analyze performance results on several simulation scenarios, such as the production of an ejecta cloud from shock-loaded metallic surfaces, using a large number of nodes equipped by Intel Xeon Phi Knights Landing processors. Performance obtained with our new Molecular Dynamics code achieves speedups greater than 1.38 against the state-of-the-art LAMMPS implementation. (C) 2020 Published by Elsevier B.V.
JOURNAL OF APPLIED PHYSICS, AMER INST PHYSICS, 2020
abstract
Abstract
We perform very large scale molecular dynamics (MD) simulations to investigate the ejection process from shock-loaded tin surfaces in regimes where the metal first undergoes solid to solid phase transitions and then melts on release. In these conditions, a classical two-wave structure propagates within the metal. When it interacts with the surface, our MD simulations reveal very different behaviors. If the surface geometry is perfectly flat or contains almost flat perturbations (sinusoidal type), a solid cap made of crystallites forms at the free surface, over a thickness of a few tens of nanometers. This surface cap melts more slowly than the bulk, and as a result, the ejection process is greatly slowed down. If the surface geometry contains V-shape geometrical perturbations, the oblique interaction of the incident shock wave with the planar interface of the defect leads to a sharp increase of temperature at the defect's bottom. At this place, the metal undergoes a solid to liquid phase change over the entire length of the groove, and this promotes the ejection of matter in the form of sheets of liquid metal. However, this phase change is not spatially uniform, and the sheets keep in memory this process by exhibiting a non-uniform leading edge and large ripples. These ripples grow over time, which ends up causing the fragmentation of the sheets as they develop. In this case, the fragmentation is non-uniform, and it differs from the rather uniform fragmentation process observed when the metal directly melts upon receiving the shock.
université Paris-Saclay, 2020
abstract
Abstract
This thesis addresses the problem of the automatic generation of purely hexahedral meshes for simulation codes when having a mesh carrying volume fraction data as an input, meaning that there can be several materials inside one cell. The proposed approach should create an hexahedral mesh where each cell corresponds to a single material, and where interfaces between materials form smooth surfaces. From a theoretical standpoint, we aim at adapting and extending state-of-the-art techniques and we apply them on examples, some classically issued from CAD models (and imprinted onto a mesh to obtain volume fractions), some procedurally generated cases and others in an intercode capacity where we take the results of a first simulation code to be our inputs. We first define a metric that allows the evaluation of our (or others') results and a method to improve those; we then introduce a discrete material interface reconstruction method inspired from the scientific visualization field and finally we present an algorithmic pipeline, called {sc ELG}, that offers a guarantee on the mesh quality by performing geometrical and topological mesh adaptation.
IGARSS 2020 - 2020 IEEE International Geoscience and Remote Sensing Symposium, 2020
abstract
Abstract
The absorption positions and shapes are key information to identify and characterize a mineral from its reflectance spectrum. With the development of new airborne and satellite-borne hyperspectral sensors, automatic methods have to be developed to extract and analyze this useful information. A flexible deconvolution procedure, able to deal with various sensor characteristics and a wide variety of minerals of interest, is proposed. The approach is based on the sparse representation of the spectrum and the use of a greedy algorithm, the Non-Negative Orthogonal Matching Pursuit algorithm. First, NNOMP is adapted to deal with a parameteric physical model of mineral reflectance spectra. Then, noise statistical information is taken into account to improve the detection of small absorptions while minimizing overfitting effects. The procedure is tested on real data from two quarries in France. Results show the potential of our procedure for the estimation of a consistent number of absorptions whose parameters can be used to analyze the mineralogy.
Computer Methods in Applied Mechanics and Engineering , 2020
abstract
Abstract
Numerical codes using the lattice Boltzmann methods (LBM) for simulating one- or two-phase flows are widely compiled and run on graphical process units. However, those computational units necessitate to re-write the program by using a low-level language which is suited to those architectures (e.g. CUDA for GPU NVIDIA®or OpenCL). In this paper we focus our effort on the performance portability of LBM i.e. the possibility of writing LB algorithms with a high-level of abstraction while remaining efficient on a wide range of architectures such as multicores x86, GPU NVIDIA®, ARM, and so on. For such a purpose, implementation of LBM is carried out by developing a unique code, LBM_saclay written in the C++ language, coupled with the Kokkos library for performance portability in the context of High Performance Computing. In this paper, the LBM is used to simulate a phase-field model for two-phase flow problems with phase change. The mathematical model is composed of the incompressible Navier–Stokes equations coupled with the conservative Allen–Cahn model. Initially developed in the literature for immiscible binary fluids, the model is extended here to simulate phase change occurring at the interface between liquid and gas. For that purpose, a heat equation is added with a source term involving the time derivative of the phase field. In the phase-field equation a source term is added to approximate the mass production rate at the interface. Several validations are carried out to check step-by-step the implementation of the full model. Finally, computational times are compared on CPU and GPU platforms for the physical problem of film boiling.
Abstract
Executable domain-specific languages (DSLs) enable the execution of behavioral models. While an execution is mostly driven by the model content (e.g., control structures), many use cases require interacting with the running model, such as simulating scenarios in an automated or interactive way, or coupling the model with other models of the system or environment. The management of these interactions is usually hardcoded into the semantics of the DSL, which prevents its reuse for other DSLs and the provision of generic interaction-centric tools (e.g., event injector). In this paper, we propose a metalanguage for complementing the definition of executable DSLs with explicit behavioral interfaces to enable external tools to interact with executed models in a unified way. We implemented the proposed metalanguage in the GEMOC Studio and show how behavioral interfaces enable the realization of tools that are generic and thus usable for different executable DSLs.
Automated Software Engineering 27(3), 2020
abstract
Abstract
Model transformations play an important role in the evolution of systems in various fields such as healthcare, automotive and aerospace industry. Thus, it is important to check the correctness of model transformation programs. Several approaches have been proposed to generate test cases for model transformations based on different coverage criteria (e.g., statements, rules, metamodel elements, etc.). However, the execution of a large number of test cases during the evolution of transformation programs is time-consuming and may include a lot of overlap between the test cases. In this paper, we propose a test case selection approach for model transformations based on multi-objective search. We use the non-dominated sorting genetic algorithm (NSGA-II) to find the best trade-offs between two conflicting objectives: (1) maximize the coverage of rules and (2) minimize the execution time of the selected test cases. We validated our approach on several evolution cases of medium and large ATLAS Transformation Language programs.
Abstract
Runtime monitoring is a fundamental technique used throughout the lifecycle of a system for many purposes, such as debugging, testing, or live analytics. While runtime monitoring for general purpose programming languages has seen a great amount of research, developing such complex facilities for any executable Domain Specific Language (DSL) remains a challenging, reoccurring and error prone task. A generic solution must both support a wide range of executable DSLs (xDSLs) and induce as little execution time overhead as possible. Our contribution is a fully generic approach based on a temporal property language with a semantics tailored for runtime verification. Properties can be compiled to efficient runtime monitors that can be attached to any kind of executable discrete event model within an integrated development environment. Efficiency is bolstered using a novel combination of structural model queries and complex event processing. Our evaluation on 3 xDSLs shows that the approach is applicable with an execution time overhead of 121% (on executions shorter than 1s), to 79% (on executions shorter than 20s) making it suitable for model testing and debugging.
Astronomy and Astrophysics, Volume 643, 2020
abstract
Abstract
We present the Extreme-Horizon (EH) cosmological simulation, which models galaxy formation with stellar and active galactic nuclei (AGN) feedback and uses a very high resolution in the intergalactic and circumgalactic medium. Its high resolution in low-density regions results in smaller-size massive galaxies at a redshift of z = 2, which is in better agreement with observations compared to other simulations. We achieve this result thanks to the improved modeling of cold gas flows accreting onto galaxies. In addition, the EH simulation forms a population of particularly compact galaxies with stellar masses of 10 ¹⁰⁻¹¹ M⊙ that are reminiscent of observed ultracompact galaxies at z ≃ 2. These objects form primarily through repeated major mergers of low-mass progenitors and independently of baryonic feedback mechanisms. This formation process can be missed in simulations with insufficient resolution in low-density intergalactic regions.
Continuum Mechanics, Applied Mathematics and Scientific Computing: Godunov's Legacy, 2020
abstract
Abstract
We are interested in the numerical approximation of the shallow water equations in two space dimensions. We propose a well-balanced, all-regime, and positive scheme. Our approach is based on a Lagrange-projection decomposition which allows to naturally decouple the acoustic and transport terms.
2019
Comput. Fluids, p. 372 - 393, 2019
Tools for High Performance Computing 2017, Springer International Publishing, p. 57-71, 2019
abstract
Abstract
Several instrumentation interfaces have been developed for parallel programs to make observable actions that take place during execution and to make accessible information about the program’s behavior and performance. Following in the footsteps of the successful profiling interface for MPI (PMPI), new rich interfaces to expose internal operation of MPI (MPI-T) and OpenMP (OMPT) runtimes are now in the standards. Taking advantage of these interfaces requires tools to selectively collect events from multiples interfaces by various techniques: function interposition (PMPI), value read (MPI-T), and callbacks (OMPT). In this paper, we present the unified instrumentation pipeline proposed by the MALP infrastructure that can be used to forward a variety of fine-grained events from multiple interfaces online to multi-threaded analysis processes implemented orthogonally with plugins. In essence, our contribution complements “front-end” instrumentation mechanisms by a generic “back-end” event consumption interface that allows “consumer” callbacks to generate performance measurements in various formats for analysis and transport. With such support, online and post-mortem cases become similar from an analysis point of view, making it possible to build more unified and consistent analysis frameworks. The paper describes the approach and demonstrates its benefits with several use cases.
Int. J. High Perform. Comput. Appl., 2019
Parallel Comput., p. 204-219, 2019
OpenMP: Conquering the Full Hardware Spectrum - 15th International Workshop on OpenMP, IWOMP 2019, Auckland, New Zealand, September 11-13, 2019, Proceedings, Springer, p. 231-245, 2019
abstract
Abstract
The advent of the multicore era led to the duplication of functional units through an increasing number of cores. To exploit those processors, a shared-memory parallel programming model is one possible direction. Thus, OpenMP is a good candidate to enable different paradigms: data parallelism (including loop-based directives) and control parallelism, through the notion of tasks with dependencies. But this is the programmer responsibility to ensure that data dependencies are complete such as no data races may happen. It might be complex to guarantee that no issue will occur and that all dependencies have been correctly expressed in the context of nested tasks. This paper proposes an algorithm to detect the data dependencies that might be missing on the OpenMP task clauses between tasks that have been generated by different parents. This approach is implemented inside a tool relying on the OMPT interface.
Proceedings of the 26th European MPI Users’ Group Meeting, EuroMPI 2019, Zürich, Switzerland, September 11-13, 2019, ACM, p. 10:1-10:10, 2019
CoRR, 2019
Journal of Computational Physics, p. 339-364, 2019
Proceedings of the 26th European MPI Users' Group Meeting, EuroMPI 2019, Zürich, Switzerland, September 11-13, 2019, ACM, p. 2:1-2:10, 2019
Journal of Computer Languages, Elsevier, p. 100919, 2019
2019
Proceedings of the 28th International Meshing Roundtable, 2019
abstract
Abstract
Hexahedral mesh generation using overlay grid methods has the benefit of being fully automatic, requiring minimal user input. These methods follow a mesh-first approach where an initial mesh, usually a grid, is used to overlay the reference geometry. Procedures to modify the initial mesh are then employed to best capture the geometry to get a conformal all-hex mesh [1\]. One of the main drawbacks of those methods is the resulting mesh quality. While the interior of the mesh remains the same as the initial mesh, cells located at the material interfaces can end up quite deformed or even inverted, making the mesh totally useless for most numerical simulation codes. Considering an input mesh carrying volume fractions of the materials, the main purpose of the presented work is to ensure a minimal cell quality. Our method draws upon the overlay grid pipeline described in [2\] where several steps (cell assignment correction, interface reconstruction, mesh adaptation) are altered to control cell quality.
Dual-based user-guided hexahedral block generation using frame fields, 2019
abstract

Abstract
Block structured hexahedral meshing is required for many applications but remains unreachable in an automatic manner for realistic simulation models. In practice, true industrial cases are handled using complex and rich interactive software, and generating a block structure for a mechanical CAD part can require several days to weeks for an expert engineer. For many years now, several scientific works have demonstrated that 3D frame fields are a very powerful tool for hexahedral meshing. These works remain mainly theoretical and their application is limited to simple 3D models. In this paper, we propose to provide the necessary components to build an interactive tool using frame fields. The principle of the approach is to build a valid dual structure made of 3D dual sheets, which are aligned along a 3D frame field, and then to convert this dual structure into its primal hexahedral block structure.
Surveys in Geophysics 40, 431–470, 2019
abstract
Abstract
Natural and anthropogenic hazards have the potential to impact all aspects of society including its economy and the environment. Diagnostic data to inform decision-making are critical for hazard management whether for emergency response, routine monitoring or assessments of potential risks. Imaging spectroscopy (IS) has unique contributions to make via the ability to provide some key quantitative diagnostic information. In this paper, we examine a selection of key case histories representing the state of the art to gain an insight into the achievements and perspectives in the use of visible to shortwave infrared IS for the detection, assessment and monitoring of a selection of significant natural and anthropogenic hazards. The selected key case studies examined provide compelling evidence for the use of the IS technology and its ability to contribute diagnostic information currently unattainable from operational spaceborne Earth observation systems. User requirements for the applications were also evaluated. The evaluation showed that the projected launch of spaceborne IS sensors in the near-, mid and long term future, together with the increasing availability, quality and moderate cost of off the shelf sensors, the possibilities to couple unmanned autonomous systems with miniaturized sensors, should be able to meet these requirements. The challenges and opportunities for the scientific community in the future when such data become available will then be ensuring consistency between data from different sensors, developing techniques to efficiently handle, process, integrate and deliver the large volumes of data, and most importantly translating the data to information that meets specific needs of the user community in a form that can be digested/understood by them. The latter is especially important to transforming the technology from a scientific to an operational tool. Additionally, the information must be independently validated using current trusted practices and uncertainties quantified before IS derived measurement can be integrated into operational monitoring services.
Wear, Elsevier, p. 1102-1109, 2019
abstract
Abstract
Secondary air systems of civil aircraft engines require labyrinth seals with a minimum gap clearance for optimal functioning. In the case of high speed contact during the engine running-in period, an abradable material is deposited on the stationary part of the seal to limit the damage of the rotating shaft, which is made of a titanium alloy. Such situations are potentially critical for the seal; hence, the present study aims to observe the material behaviour during these contact conditions and to establish the tribological circuit of a third body through the interface. A high-speed contact test rig was developed to recreate contact conditions occurring in an aircraft engine. Two contact configurations occurring in different locations of the engine, with different materials and surface areas were explored. Thermal and mechanical instrumentation were used in each test. The influence of the contact geometry and the test conditions show that material flows through the contact determine the life cycle of the contact (by establishing a balance between the source, internal and material flow) and allows for the control of the thermomechanical constraints in a high-speed contact.
Proceedings of the 7th International Conference on Fracture Fatigue and Wear: FFW 2018, 9-10 July 2018, Ghent University, Belgium, Springer, p. 638-660, 2019
abstract
Abstract
Civil aircraft engines present a wide range of labyrinth seals to ensure a good airtightness between the different components of the secondary air system. An increase in efficiency requires lower clearances gaps. As a consequence, brief contacts between rotating and stationary parts may occur especially during the engine running-in period. Such events can cause critical situations (seizure…) depending on the working conditions. In this paper, experimental simulations by means of a high-speed contact test device (76 m s−1) was developed to precisely recreate the friction conditions occurring in a turboshaft labyrinth seal and to better understand the material behavior in such tribological cases. This device was instrumented to carry out mechanical (axial and tangential forces and torque) and thermal measurements (IR camera and pyrometer). An experimental campaign was carried to study the contact between a Ti6Al4V rotor and an abradable coating of Al-Si polyester. Presented results show the complex interactions that strongly depend on the way the worn material behaves in the contact area. Local interaction dynamics are analysed with regards to mechanical and thermal measurements with different rotating speeds, incursion depths, and interaction speeds.
PHYSICAL REVIEW E 99(5), 2019
abstract
Abstract
It is still not known whether solutions to the Navier-Stokes equation can develop singularities from regular initial conditions. In particular, a classical and unsolved problem is to prove that the velocity field is Hölder continuous with some exponent h<1 (i.e., not necessarily differentiable) at small scales. Different methods have already been proposed to explore the regularity properties of the velocity field and the estimate of its Hölder exponent h. A first method is to detect potential singularities via extrema of an “inertial” dissipation D*=limℓ→0DℓI that is independent of viscosity [Duchon and Robert, Nonlinearity 13, 249 (2000)]. Another possibility is to use the concept of multifractal analysis that provides fractal dimensions of the subspace of exponents h. However, the multifractal analysis is a global statistical method that only provides global information about local Hölder exponents, via their probability of occurrence. In order to explore the local regularity properties of a velocity field, we have developed a local statistical analysis that estimates locally the Hölder continuity. We have compared outcomes of our analysis with results using the inertial energy dissipation DℓI. We observe that the dissipation term indeed gets bigger for velocity fields that are less regular according to our estimates. The exact spatial distribution of the local Hölder exponents however shows nontrivial behavior and does not exactly match the distribution of the inertial dissipation.
The Astrophysical Journal, Volume 876, Number 2 (144), 2019
abstract
Abstract
By generalizing the theory of convection to any type of thermal and compositional source terms (diabatic processes), we show that thermohaline convection in Earth's oceans, fingering convection in stellar atmospheres, and moist convection in Earth's atmosphere are derived from the same general diabatic convective instability. We also show that "radiative convection" triggered by the CO/CH4 transition with radiative transfer in the atmospheres of brown dwarfs is analogous to moist and thermohaline convection. We derive a generalization of the mixing-length theory to include the effect of source terms in 1D codes. We show that CO/CH4 "radiative" convection could significantly reduce the temperature gradient in the atmospheres of brown dwarfs similarly to moist convection in Earth's atmosphere, thus possibly explaining the reddening in brown dwarf spectra. By using idealized 2D hydrodynamic simulations in the Ledoux unstable regime, we show that compositional source terms can indeed provoke a reduction of the temperature gradient. The L/T transition could be explained by a bifurcation between the adiabatic and diabatic convective transports and seen as a giant cooling crisis: an analog of the boiling crisis in liquid/steam-water convective flows. This mechanism, with other chemical transitions, could be present in many giant and Earth-like exoplanets. The study of the impact of different parameters (effective temperature, compositional changes) on CO/CH4 radiative convection and the analogy with Earth moist and thermohaline convection is opening the possibility of using brown dwarfs to better understand some aspects of the physics at play in the climate of our own planet.
The Astrophysical Journal, Volume 875, Number 2, 2019
abstract
Abstract
Convection is an important physical process in astrophysics well-studied using numerical simulations under the Boussinesq and/or anelastic approximations. However, these approaches reach their limits when compressible effects are important in the high-Mach flow regime, e.g., in stellar atmospheres or in the presence of accretion shocks. In order to tackle these issues, we propose a new high-performance and portable code called “ARK” with a numerical solver well suited for the stratified compressible Navier–Stokes equations. We take a finite-volume approach with machine precision conservation of mass, transverse momentum, and total energy. Based on previous works in applied mathematics, we propose the use of a low-Mach correction to achieve a good precision in both low and high-Mach regimes. The gravity source term is discretized using a well-balanced scheme in order to reach machine precision hydrostatic balance. This new solver is implemented using the Kokkos library in order to achieve high-performance computing and portability across different architectures (e.g., multi-core, many-core, and GP-GPU). We show that the low-Mach correction allows to reach the low-Mach regime with a much better accuracy than a standard Godunov-type approach. The combined well-balanced property and the low-Mach correction allowed us to trigger Rayleigh–Bénard convective modes close to the critical Rayleigh number. Furthermore, we present 3D turbulent Rayleigh–Bénard convection with low diffusion using the low-Mach correction leading to a higher kinetic energy power spectrum. These results are very promising for future studies of high Mach and highly stratified convective problems in astrophysics.
2018
J. Comput. Phys., p. 268 - 301, 2018
Euro-Par 2018: Parallel Processing - 24th International Conference on Parallel and Distributed Computing, Turin, Italy, August 27-31, 2018, Proceedings, Springer, p. 616-627, 2018
Euro-Par 2018: Parallel Processing - 24th International Conference on Parallel and Distributed Computing, Turin, Italy, August 27-31, 2018, Proceedings, Springer, p. 560-572, 2018
Proceedings of the 25th European MPI Users’ Group Meeting, Barcelona, Spain, September 23-26, 2018, ACM, p. 12:1-12:11, 2018
Journal of Computational Physics, p. 228-257, 2018
Euro-Par 2018: Parallel Processing Workshops - Euro-Par 2018 International Workshops, Turin, Italy, August 27-28, 2018, Revised Selected Papers, Springer, p. 123-133, 2018
Proceedings of the International Symposium on Memory Systems, MEMSYS 2018, Old Town Alexandria, VA, USA, October 01-04, 2018, ACM, p. 169-182, 2018
Université Grenoble Alpes, 2018-02
ISAV 18: Proceedings of the Workshop on In Situ Infrastructures for Enabling Extreme-Scale Analysis and Visualization, p. 7-12, 2018
Proceedings of the 11th ACM SIGPLAN International Conference on Software Language Engineering, p. 200-204, 2018
2018 Proceedings of the SIAM Workshop on Combinatorial Scientific Computing (CSC), Society for Industrial and Applied Mathematics, p. 66-75, 2018-01
Abstract
In this work, we provide a new post-processing procedure for automatically adjusting node locations of an all-hex mesh to better match the volume of a reference geometry. This process is particularly well-suited for mesh-first approaches, as overlay grid ones. In practice, hexahedral meshes generated via an overlay grid procedure, where a precise reference geometry representation is unknown or is impractical to use, do not provide for precise volumetric preservation. A discrete volume fraction representation of the reference geometry MI on an overlay grid is compared with a volume fraction representation of a 3D finite element mesh MO. This work introduces the notion of localized discrepancy between MI and MO and uses it to design a procedure that relocates mesh nodes to more accurately match a reference geometry. We demonstrate this procedure on a wide range of hexahedral meshes generated with the Sculpt code and show improved volumetric preservation while still maintaining acceptable mesh quality.
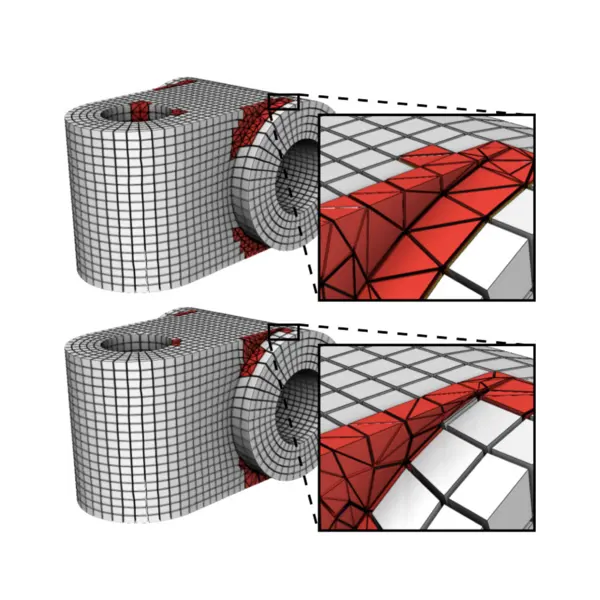
Abstract
We propose a robust pipeline that can generate hex-dominant meshes from any global parameterization of a tetrahedral mesh. We focus on robustness in order to be able to benchmark different parameterizations on a large database. Our main contribution is a new method that integrates the hexahedra (extracted from the parameterization) into the original object. The main difficulty is to produce the boundary of the result, composed of both faces of hexahedra and tetrahedra. Obviously, this surface must be a good approximation of the original object but, more importantly, it must be possible to remesh the volume bounded by this surface minus the extracted hexahedra (called void). We enforce these properties by carefully tracking and eliminating all possibilities of failure at each step of our pipeline. We tested our method on a large collection of objects (200+) with different settings. In most cases, we obtained results of very good quality as compared to the state-of-the-art solutions. To ease reproducing our results and benchmarks, we provide a C++ implementation of the pipeline in the supplemental materials.
ZAMM Journal of applied mathematics and mechanics (Zeitschrift für angewandte Mathematik und Mechanik), vol 98-3, p. 448-453, 2018
Applied Mathematics and Computation, vol 332, p. 160-166, 2018
2018
abstract
Abstract
This paper is focused on the retrieval of industrial aerosol optical thickness (AOT) and microphysical properties by means of airborne imaging spectroscopy. Industrial emissions generally lead to optically thin plumes requiring an adapted detection method taking into account the weak proportion of particles sought in the atmosphere. To this end, a semi-analytical model combined with the Cluster-Tuned Matched Filter (CTMF) algorithm is presented to characterize those plumes, requiring the knowledge of the soil under the plume. The model allows the direct computation of the at-sensor radiance when a plume is included in the radiative transfer. When applied to industrial aerosol classes as defined in this paper, simulated spectral radiances can be compared to ‘real’ MODTRAN (Moderate Resolution Atmospheric Transmission) radiances using the Spectral Angle Mapper (SAM). On the range from 0.4 to 0.7 µm, for three grounds (water, vegetation, and bright one), SAM scores are lower than 0.043 in the worst case (a both absorbing and scattering particle over a bright ground), and usually lower than 0.025. The darker the ground reflectance is, the more accurate the results are (typically for reflectance lower than 0.3). Concerning AOT retrieval capabilities, with a pre-calculated model for a reference optical thickness of 0.25, we are able to retrieve plume AOT at 550 nm in the range 0.0 to 0.4 with an error usually ranging between 9% and 13%. The first test case is a CASI (Compact Airborne Spectrographic Imager) image acquired over the metallurgical industry of Fos-sur-Mer (France). First results of the use of the model coupled with CTMF algorithm reveal a scattering aerosol plume with particle sizes increasing with the distance from the stack (from detection score of 54% near the stack for particles with a diameter of 0.1 µm, to 69% away from it for 1.0 µm particles). A refinement is made then to estimate more precisely aerosol plume properties, using a multimodal distribution based on the previous results. It leads to find a mixture of sulfate and brown carbon particles with a plume AOT ranging between 0.2 and 0.5. The second test case is an AHS (Airborne Hyperspectral Scanner) image acquired over the petrochemical site of Antwerp (Belgium). The first CTMF application results in detecting a brown carbon aerosol of 0.1 µm mode (detection score is 51%). Refined results show the evolution of the AOT decreasing from 0.15 to 0.05 along the plume for a mixture of brown carbon fine mode and 0.3 µm radius of sulfate aerosol.
Remote Sensing 10(1):146, 2018
abstract
Abstract
The identification and mapping of the mineral composition of by-products and residues on industrial sites is a topic of growing interest because it may provide information on plant-processing activities and their impact on the surrounding environment. Imaging spectroscopy can provide such information based on the spectral signatures of soil mineral markers. In this study, we use the automatized Gaussian model (AGM), an automated, physically based method relying on spectral deconvolution. Originally developed for the short-wavelength infrared (SWIR) range, it has been extended to include information from the visible and near-infrared (VNIR) range to take iron oxides/hydroxides into account. We present the results of its application to two French industrial sites: (i) the Altéo Environnement site in Gardanne, southern France, dedicated to the extraction of alumina from bauxite; and (ii) the Millennium Inorganic Chemicals site in Thann, eastern France, which produces titanium dioxide from ilmenite and rutile, and its associated Séché éco Services site used to neutralize the resulting effluents, producing gypsum. HySpex hyperspectral images were acquired over Gardanne in September 2013 and an APEX image was acquired over Thann in June 2013. In both cases, reflectance spectra were measured and samples were collected in the field and analyzed for mineralogical and chemical composition. When applying the AGM to the images, both in the VNIR and SWIR ranges, we successfully identified and mapped minerals of interest characteristic of each site: bauxite, Bauxaline® and alumina for Gardanne; and red and white gypsum and calcite for Thann. Identifications and maps were consistent with in situ measurements.
CIMNE, p. 1314, 2018
Journal of Physics: Conference Series, Volume 1125, Joint Varenna-Lausanne International Workshop on the Theory of Fusion Plasmas 2018 27–31 August 2018, Varenna, Italy, 2018
abstract
Abstract
This contribution deals with the fluid modeling of multicomponent magnetized plasmas in thermo-chemical non-equilibrium from the partially- to fully-ionized collisional regimes, aiming at the predictive simulation of magnetic reconnection in Sun chromosphere conditions. Such fluid models are required for large-scale simulations by relying on high performance computing. The fluid model is derived from a kinetic theory approach, yielding a rigorous description of the dissipative and non-equilibrium effects and a well-identified mathematical structure. We start from a general system of equations that is obtained by means of a multiscale Chapman-Enskog method, based on a non-dimensional analysis accounting for the mass disparity between the electrons and heavy particles, including the influence of the electromagnetic field and transport properties. The latter are computed by using a spectral Galerkin method based on a converged Laguerre-Sonine polynomial approximation. Then, in the limit of small Debye length with respect to the characteristic scale in the Sun chromosphere, we derive a two-temperature single-momentum multicomponent diffusion model coupled to Maxwell's equations, which is able to describe fully- and partially-ionized plasmas, beyond the multi-fluid model of Braginskii, valid for the whole range of the Sun chromosphere conditions. The second contribution is the development and verification of an accurate and robust numerical strategy that is based on CanoP, a massively parallel code with adaptive mesh refinement capability, which is able to cope with the full spectrum of scales of the magnetic reconnection process, without additional constraint on the time steps compared to single-fluid Magnetohydrodynamics (MHD) models. The final contribution is a study of the physics of magnetic reconnection in collaboration with the heliophysics team of NASA Ames Research Center. We show that the model and methods allow us to retrieve the results of usual single-fluid MHD models in the highly collisional case at equilibrium, while achieving a more detailed physics description relevant to such applications in the weakly collisional case, where non-equilibrium effects become important.
14th European Conference on Modelling Foundations and Applications, 2018
abstract
Abstract
Recent approaches contribute facilities to breathe life into metamodels, thus making behavioral models directly executable. Such facilities are particularly helpful to better utilize a model over the time dimension, e.g., for early validation and verification. However, when even a small change is made to the model, to the language definition (e.g., semantic variation points), or to the external stimuli of an execution scenario, it remains difficult for a designer to grasp the impact of such a change on the resulting execution trace. This prevents accessible trade-off analysis and design-space exploration on behavioral models. In this paper, we propose a set of formally defined operators for analyzing execution traces. The operators include dynamic trace filtering, trace comparison with diff computation and visualization, and graph-based view extraction to analyze cycles. The operators are applied and validated on a demonstrative example that highlight their usefulness for the comprehension specific aspects of the underlying traces.
IEEE Scientific Visualization Conference, 2018
abstract
Abstract
We present a highly efficient solution to interact with the Deep Water Impact Ensemble Data Set provided for the Scientific Visualization Contest 2018. Interactive visualization is made possible on one core of a laptop with the full resolution and the same accuracy as in the original data set, when originally 256 up to 2048 supercomputer nodes were required to generate the data. As far as we know this is the only way to achieve full-resolution exploration on a laptop. We first expose how our approach allows more efficient visualization by using the Tree-Based Adaptive Mesh Refinement grid data structure we introduced in VTK, vtkHyperTreeGrid [1], as compared to structured or unstructured approaches. Then we elaborate on the visualization capabilities offered by vtkHyperTreeGrid-optimized algorithms and the performance achieved on the limited resources available on a laptop. Next, we present how the hierarchical structure makes possible novel ways of exploring data interactively and helps achieve accelerated data exploration by hierarchically driving decimation of values. Finally, we show preliminary results of interactive volume rendering using splatting.
Thèse de Doctorat de l'Université Paris-Saclay, 2018
abstract
Abstract
On étudie dans le cadre de la thèse une famille de schémas numériques permettant de résoudre les équations de Saint-Venant. Ces schémas utilisent une décomposition d'opérateur de type Lagrange-projection afin de séparer les ondes de gravité et les ondes de transport. Un traitement implicite du système acoustique (relié aux ondes de gravité) permet aux schémas de rester stable avec de grands pas de temps. La correction des flux de pression rend possible l'obtention d'une solution approchée précise quel que soit le régime d'écoulement vis-à-vis du nombre de Froude. Une attention toute particulière est portée sur le traitement du terme source qui permet la prise en compte de l'influence de la topographie. On obtient notamment la propriété dite équilibre permettant de conserver exactement certains états stationnaires, appelés état du "lac au repos". Des versions 1D et 2D sur maillages non-structurés de ces méthodes ont été étudiées et implémentées dans un cadre volumes finis. Enfin, une extension vers des méthodes ordres élevés Galerkin discontinue a été proposée en 1D avec des limiteurs classiques ainsi que combinée avec une boucle MOOD de limitation a posteriori.
2018 International Conference on High Performance Computing and Simulation (HPCS), p. 1059-1060, 2018
abstract
Abstract
The use of object storage in the HPC world becomes a common case as it enables to overcome some POSIX limitations in scalability and performance. Indeed, object stores use a flat namespace, avoiding hierarchy in access requests and the cost of maintaining dependencies between multiple entries. Object stores also differentiate data flow from metadata flow, providing better concurrency and throughput. They can store trillions of objects and each object has its own customized metadata attributes so these metadata can be richer than POSIX attributes.
Proceedings of the 4th ACM International Conference of Computing for Engineering and Sciences, Association for Computing Machinery, 2018
abstract
Abstract
Simulation is the most appropriate technique to evaluate the performance of current data storage systems and predict it for the future ones as part of data centers or cloud infrastructures. It assesses the potential of a system to meet the users requirements in terms of storage capacity, devices heterogeneity, delivered performance and robustness. We developed a simulation tool called OGSSim to address efficiently these criteria within a reduced execution time. But the number of threads on the test machine put an upper bound to the size of the simulated systems. To push this limitation and improve the simulation time, we define in this paper a parallel version of OGSSim. We explain how the parallelization process generate both design and implementation challenges due to the multi-node environment and the related communications and how MPI and ZeroMQ libraries respectively help us to address those challenges.
2017
Chapman; Hall/CRC, p. 45-74, 2017
46th International Conference on Parallel Processing Workshops, ICPP Workshops 2017, Bristol, United Kingdom, August 14-17, 2017, IEEE Computer Society, p. 251-260, 2017
Scaling OpenMP for Exascale Performance and Portability - 13th International Workshop on OpenMP, IWOMP 2017, Stony Brook, NY, USA, September 20-22, 2017, Proceedings, Springer, p. 203-216, 2017
Parallel Computing is Everywhere, Proceedings of the International Conference on Parallel Computing, ParCo 2017, 12-15 September 2017, Bologna, Italy, IOS Press, p. 465-474, 2017
29th International Symposium on Computer Architecture and High Performance Computing, SBAC-PAD 2017, Campinas, Brazil, October 17-20, 2017, IEEE Computer Society, p. 177-184, 2017
Journal of Computational Physics, 2017
Procedia Engineering, p. 258-270, 2017-01
abstract
Abstract
We propose a new post-processing procedure for automatically adjusting node locations of an all-hex mesh to better match the volume of a reference geometry. Hexahedral meshes generated via an overlay grid procedure, where a precise reference geometry representation is unknown or is impractical to use, do not provide for precise volumetric preservation. A discrete volume fraction representation of the reference geometry MI on an overlay grid is compared with a volume fraction representation of a 3D finite element mesh MO. This work proposes a procedure that uses the localized discrepancy between MI and MO to drive node relocation operations to more accurately match a reference geometry. We demonstrate this procedure on a wide range of hexahedral meshes generated with the Sculpt code and show improved volumetric preservation while still maintaining acceptable mesh quality.
Euro-Par 2017: Parallel Processing, Springer International Publishing, p. 594-606, 2017
abstract
Abstract
In this paper, we present a fine-grained multi-stage metric-based triangular remeshing algorithm on manycore and NUMA architectures. It is motivated by the dynamically evolving data dependencies and workload of such irregular algorithms, often resulting in poor performance and data locality at high number of cores. In this context, we devise a multi-stage algorithm in which a task graph is built for each kernel. Parallelism is then extracted through fine-grained independent set, maximal cardinality matching and graph coloring heuristics. In addition to index ranges precalculation, a dual-step atomic-based synchronization scheme is used for nodal data updates. Despite its intractable latency-boundness, a good overall scalability is achieved on a NUMA dual-socket Intel Haswell and a dual-memory Intel KNL computing nodes (64 cores). The relevance of our synchronization scheme is highlighted through a comparison with the state-of-the-art.
JOURNAL OF APPLIED PHYSICS, AMER INST PHYSICS, 2017
abstract
Abstract
We compare, at similar scales, the processes of microjetting and ejecta production from shocked roughened metal surfaces by using atomistic and continuous approaches. The atomistic approach is based on very large scale molecular dynamics (MD) simulations with systems containing up to 700 x 10(6) atoms. The continuous approach is based on Eulerian hydrodynamics simulations with adaptive mesh refinement; the simulations take into account the effects of viscosity and surface tension, and the equation of state is calculated from the MD simulations. The microjetting is generated by shock-loading above its fusion point a three-dimensional tin crystal with an initial sinusoidal free surface perturbation, the crystal being set in contact with a vacuum. Several samples with homothetic wavelengths and amplitudes of defect are simulated in order to investigate the influence of viscosity and surface tension of the metal. The simulations show that the hydrodynamic code reproduces with very good agreement the profiles, calculated from the MD simulations, of the ejected mass and velocity along the jet. Both codes also exhibit a similar fragmentation phenomenology of the metallic liquid sheets ejected, although the fragmentation seed is different. We show in particular, that it depends on the mesh size in the continuous approach. Published by AIP Publishing.
Abstract
In this article, the scientific life of D. Gogny is recounted by several collaborators. His strong involvement in researches related to various fields of physics (such as nuclear, atomic and plasma physics as well as electromagnetism) appears clearly, as well as the progresses made in the understanding of fundamental physics.
IEEE Trans. AP, vol 65, n 2, p. 794-804, 2017
Discrete and continuous dynamical systems ,Volume 37, Number 3, 2017
19th International Conference on Solid-State Sensors, Actuators and Microsystems (TRANSDUCERS), IEEE, p. 520-523, 2017
abstract
Abstract
This paper reports a novel method to evaluate and improve the reliability of mechanical stops during design and validation phases of MEMS (Micro ElectroMechanical System) in shock environments. Firstly, inplane stop contact behavior is modeled through both steady-state and dynamic mechanical FEM (Finite-Element Modeling) to validate physics package and to extract nonlinear stiffness and stress distribution as functions of contact force applied on a cylinder-to-plane Hertz contact type. Then, the transient response of a MEMS including stops behavior is modeled with a lumped impact element approach which allows to compute contact force as a function of applied half-sine shock parameters. Finally, several shock tests have been performed on numerous devices embedding previously modeled stops to evaluate experimental survival rate. Fitting experimental data to numerical results combined with Weibull theory exhibits a good compliance which allows to estimate silicon Weibull parameters respectively at 0.7 GPa, 1.1 GPa and 4 for threshold stress, average stress and Weibull modulus.
The Astrophysical Journal, Volume 840, Number 1, 2017
abstract
Abstract
Magnetohydrodynamic (MHD) turbulence driven by the magnetorotational instability can provide diffusive transport of angular momentum in astrophysical disks, and a widely studied computational model for this process is the ideal, stratified, isothermal shearing box. Here we report results of a convergence study of such boxes up to a resolution of $N = 256$ zones per scale height, performed on blue waters at NCSA with ramses-gpu. We find that the time and vertically integrated dimensionless shear stress $\overline{\alpha} \sim N^{-1/3}$, i.e. the shear stress is resolution dependent. We also find that the magnetic field correlation length decreases with resolution, $\lambda \sim N^{-1/2}$. This variation is strongest at the disk midplane. We show that our measurements of $\alpha$ are consistent with earlier studies. We discuss possible reasons for the lack of convergence.
Communications in Mathematical Sciences, Volume 15, Number 3, 2017
abstract
Abstract
This work focuses on the numerical approximation of the shallow water equations (SWE) using a Lagrange-projection type approach. We propose to extend to this context the recent implicit-explicit schemes developed in [C. Chalons, M. Girardin, and S. Kokh, SIAM J. Sci. Comput., 35(6):a2874–a2902, 2013], [C. Chalons, M. Girardin, and S. Kokh, Commun. Comput. Phys., to appear, 20(1):188–233, 2016] in the framework of compressible flows, with or without stiff source terms. These methods enable the use of time steps that are no longer constrained by the sound velocity thanks to an implicit treatment of the acoustic waves, and maintain accuracy in the subsonic regime thanks to an explicit treatment of the material waves. In the present setting, a particular attention will be also given to the discretization of the non-conservative terms in SWE and more specifically to the wellknown well-balanced property. We prove that the proposed numerical strategy enjoys important non linear stability properties and we illustrate its behaviour past several relevant test cases.
Journal of Systems and Software Volume 137, March 2018, Pages 261-288, 2017
abstract
Abstract
Omniscient debugging is a promising technique that relies on execution traces to enable free traversal of the states reached by a model (or program) during an execution. While a few General-Purpose Languages (GPLs) already have support for omniscient debugging, developing such a complex tool for any executable Domain Specific Language (DSL) remains a challenging and error prone task. A generic solution must: support a wide range of executable DSLs independently of the metaprogramming approaches used for implementing their semantics; be efficient for good responsiveness. Our contribution relies on a generic omniscient debugger supported by efficient generic trace management facilities. To support a wide range of executable DSLs, the debugger provides a common set of debugging facilities, and is based on a pattern to define runtime services independently of metaprogramming approaches. Results show that our debugger can be used with various executable DSLs implemented with different metaprogramming approaches. As compared to a solution that copies the model at each step, it is on average sixtimes more efficient in memory, and at least 2.2 faster when exploring past execution states, while only slowing down the execution 1.6 times on average.
2017
abstract
Abstract
We present here the result of continuation work, performed to further fulfill the vision we outlined in [Harel,Lekien,Pébaÿ-2017] for the visualization and analysis of tree-based adaptive mesh refinement (AMR) simulations, using the hypertree grid paradigm which we proposed. The first filter presented hereafter implements an adaptive approach in order to accelerate the rendering of 2-dimensional AMR grids, hereby solving the problem posed by the loss of interactivity that occurs when dealing with large and/or deeply refined meshes. Specifically, view parameters are taken into account, in order to: on one hand, avoid creating surface elements that are outside of the view area; on the other hand, utilize level-of-detail properties to cull those cells that are deemed too small to be visible with respect to the given view parameters. This adaptive approach often results in a massive increase in rendering performance. In addition, two new selection filters provide data analysis capabilities, by means of allowing for the extraction of those cells within a hypertree grid that are deemed relevant in some sense, either geometrically or topologically. After a description of these new algorithms, we illustrate their use within the Visualization Toolkit (VTK) in which we implemented them. This note ends with some suggestions for subsequent work.
2017
abstract
Abstract
We present here the first systematic treatment of the problems posed by the visualization and analysis of large-scale, parallel adaptive mesh refinement (AMR) simulations on an Eulerian grid. When compared to those obtained by constructing an intermediate unstructured mesh with fully described connectivity, our primary results indicate a gain of at least 80\% in terms of memory footprint, with a better rendering while retaining similar execution speed. In this article, we describe the key concepts that allow us to obtain these results, together with the methodology that facilitates the design, implementation, and optimization of algorithms operating directly on such refined meshes. This native support for AMR meshes has been contributed to the open source Visualization Toolkit (VTK). This work pertains to a broader long-term vision, with the dual goal to both improve interactivity when exploring such data sets in 2 and 3 dimensions, and optimize resource utilization.
Finite Volumes for Complex Applications VIII - Hyperbolic, Elliptic and Parabolic Problems, 2017
abstract
Abstract
This work considers the barotropic Euler equations and proposes a high-order conservative scheme based on a Lagrange-Projection decomposition. The high-order in space and time are achieved using Discontinuous Galerkin (DG) and Runge-Kutta (RK) strategies. The use of a Lagrange-Projection decomposition enables the use of time steps that are not constrained by the sound speed thanks to an implicit treatment of the acoustic waves (Lagrange step), while the transport waves (Projection step) are treated explicitly. We compare our DG discretization with the recent one (Renac in Numer Math 1-27, 2016, [7]) and state that it satisfies important non linear stability properties. The behaviour of our scheme is illustrated by several test cases.
2017 International Conference on High Performance Computing and Simulation (HPCS), p. 236-243, 2017
abstract
Abstract
Storage systems capacity provided by data centers do not cease to increase, currently reaching the exabyte scale using thousands of disks. In this way, the question of the resiliency of such systems becomes critical, to avoid data loss and reduce the impact of the reconstruction process on the data access time. We propose SD2S, a method to create a placement scheme for declustered RAID organizations, based on a shifting placement. It consists in the calculation of degree matrices, which represent the distance between the source sets of each couple of physical disks, thus the number of data blocks which will be reconstructed in case of a double failure. The scheme creation is made by the computation of a score function for all possible shifting offsets and the selection of the one ensuring the reconstruction of the highest percentage of data. Results show the data reconstruction distribution against the number of double failure events. Also, the overhead generated by the calculation of the shifting offsets is compared to greedy SD2S and CRUSH without replicas for systems reaching the hundred of disks. These results confirm that the selection of the best offset can lead to a complete data reconstruction giving a small overhead, especially for large systems.
2017 International Symposium on Performance Evaluation of Computer and Telecommunication Systems (SPECTS), p. 1-8, 2017
abstract
Abstract
Using simulation to study the behavior of large-scale data storage systems becomes capital to predict the performance and the reliability of any of them at a lower cost. This helps to take the right decisions before the system development and deployment. OGSSim is a simulation tool for large and heterogeneous storage systems that uses parallelism to provide informations about the behavior of such systems in a reduced time. It uses ZeroMQ communication library to implement not only the data communication but also the synchronization functions between the generated threads. These synchronization points occur during the requests parallel execution and need to be treated efficiently to ensure data coherency for the fast and accurate computation of performance metrics. In this work, different issues due to the parallel execution of our simulation tool OGSSim are presented and the adopted solutions using ZeroMQ are discussed. The impact of these solutions in term of simulation time overhead are measured considering various system configurations. The obtained results s how t hat ZeroMQ has almost no impact on the simulation time, even for complex and large configurations.
2016
J. Appl. Math. Mech., p. 660-680, 2016
ESAIM: Math. Model. Numer. Anal., EDP Sciences, p. 187-214, 2016
Proceedings of the 23rd European MPI Users’ Group Meeting, EuroMPI 2016, Edinburgh, United Kingdom, September 25-28, 2016, ACM, p. 51-63, 2016
High Performance Computing for Computational Science - VECPAR 2016 - 12th International Conference, Porto, Portugal, June 28-30, 2016, Revised Selected Papers, Springer, p. 248-255, 2016
Conférence d'informatique en Parallélisme, Architecture et Système (Compas'2016), 2016
IWOMP 2016, 2016
Oil & Gas Science and Technology - Revue d'IFP Energies nouvelles, Institut Français du Pétrole, p. 65:1-13, 2016
Conférence d'informatique en Parallélisme, Architecture et Système (Compas'2016), 2016
Euro-Par 2016: Parallel Processing - 22nd International European Conference on Parallel and Distributed Computing, Grenoble, FR, August 24-26, 2016, Proceedings, p. 196-208, 2016

Abstract
Recent methods for frame field generation in two and three dimensions are reviewed. Frame fields generated automatically in 2D and 3D are analyzed with respect to quad and hex mesh generation. Problems are identified with automatically generated frame fields that prevent mesh generation via current methods. Specifically, there exist geometries that contain limit cycles and cannot be parameterized or decomposed by separatrices of the frame field. In 3D, singularity lines occur that minimize the field curvature but do not align with the frame field. These types of singularities make it impossible to create a mesh that both follows the frame field, and simultaneously respects the singularity as an irregular node in the mesh. Specific examples are presented that illustrate these problems. For each example, streamlines are used to help visualize properties of the frame fields, problems are analyzed, and options to potentially mitigate such problems are discussed.
Thèse de doctorat, spécialité informatique, CEA, Université d'Evry-Val-d'Essonne, 2016
Oil & Gas Science and Technology--Revue d'IFP Energies nouvelles, EDP Sciences, p. 57, 2016
International Journal for Numerical Methods in Engineering, Wiley Online Library, p. 496-519, 2016
Journal of Computational Physics, Elsevier, p. 549-582, 2016
CSC 16, p. 2, 2016
Conférence d'informatique En Parallélisme, Architecture et Système (COMPAS), 2016
Comptes Rendus Mathematique, 2016
EuroPhysics Letters, 113, 2016
Journal of Sound and Vibration, vol 374, p. 185-198, 2016
Remote Sensing Letters 7(6):581-590, 2016
abstract
Abstract
Hyperspectral sensors generally acquire images in the spectral range in more than one hundred contiguous narrow channels with a (deca)metric spatial resolution. Each pixel of the image is thus associated with a continuous spectrum which can be used to identify or map surface minerals. The most powerful algorithms (e.g., USGS (United States Geological Survey) Tetracorder) run with a standardized spectral library, are often supervised and require some expert knowledge. In this paper, we present an original method for mineral identification and mapping. Its originality lies in its fully automatic functioning for the full spectral range, from initialization using spectral derivatives, to spectral deconvolution and mineral identification, with a global approach. The modelling combines exponential Gaussians, a continuum including the fundamental water absorption at and deals with overfitting to keep only the relevant Gaussians. We tested the method in the SWIR (Short-Wave InfraRed,) and for 14 minerals representative of industrial environments (e.g., quarries, mines, industries). More than 98% of the simulated spectra were correctly identified. When applied to two AVIRIS (Airborne Visible/InfraRed Imaging Spectrometer) images, results were consistent with ground truth data. The method could be improved by extending it to the VNIR (Visible and Near-InfraRed,) spectral range to include iron oxides and by managing spectral mixtures.
Photoniques, 2016
abstract
Abstract
La caractérisation des aérosols et des gaz produits par l’homme est un enjeu majeur pour la société car ces composants ont un impact direct sur la santé et le climat. Plusieurs techniques de caractérisation existent mais la télédétection aéroportée est une réponse potentiellement adaptée pour l’étude de ces sources si l’on veut avoir accès à leur expansion spatiale. De plus, l’imagerie hyperspectrale concernant tout le domaine optique, elle permet de couvrir l’ensemble des besoins nécessaires à la détection et la caractérisation des aérosols et des gaz.
2016 International Conference on High Performance Computing and Simulation (HPCS), p. 342-349, 2016
abstract
Abstract
Modern disks are very large (SSDs, HDDs) and their capacities will certainly increase in the future. Storage systems use an important number of such devices to compose storage pools and fulfil the storage capacity demands. The result is a higher probability of a failure and a longer reconstruction duration. Consequently, the whole system is penalized as the response time is higher and a second failure will generate a data loss. In this paper, we propose a new method based on block shifting layout which increases the efficiency of a RAID declustered storage system and improves its robustness in both normal and failure modes. We define four mapping rules to reach these objectives. Conducted tests reveal that exploiting the coprime property between the number of devices and the block shifting factor leads to an optimal layout. It reduces significantly the redirection time proportionally to the number of disks, reaching 50% for 1000 disks and a negligeable memory cost as we avoid the use of a redirection table. It also allows the recovery of additional data in case of a second failure during the degraded mode which gives to our proposed method a huge interest for large storage systems comparing to other existing methods.
2016 International Symposium on Performance Evaluation of Computer and Telecommunication Systems (SPECTS), p. 1-8, 2016
abstract
Abstract
Actual storage systems are very large, with complex and distributed architectural configurations, composed of various technologies devices. However, simulation, analysis and evaluation tools in the literature do not handle this complex design and these heterogeneous components. This paper presents OGSSim (Open and Generic Storage systems Simulation tool): a new simulation tool for such systems. Being generic to all devices technologies and open to diverse management strategies and architecture layouts, it fulfills all the storage systems needs in term of representativeness. Also, it has been validated against real systems, thus its accuracy makes it a useful tool for the conception of future storage systems, the choice of hardware components and the analysis of the adequacy between the applications needs and the management strategies combined with the configuration layout. This validation confirmed only a maximum of 15% of difference between real and simulated execution time. Also, OGSSim execution in a competitive time, just 3.5 sec for common workloads on a large system of 500 disks, makes it a challenging simulation and evaluation tool. Thus, it is the appropriate and accurate tool for modern storage systems conception, evaluation and maintenance.
2015
J. Comput. Phys., Academic Press, p. 28-54, 2015
Concurr. Comput. Pract. Exp., p. 1528-1539, 2015
Proceedings of the 22nd European MPI Users’ Group Meeting, EuroMPI 2015, Bordeaux, France, September 21-23, 2015, ACM, p. 3:1-3:9, 2015
Proceedings of the 22nd European MPI Users' Group Meeting, EuroMPI 2015, Bordeaux, France, September 21-23, 2015, ACM, p. 16:1-16:2, 2015
Purdue Univ., West Lafayette, IN (United States); Sandia National Lab. (SNL-NM), Albuquerque, NM (United States); Argonne National Lab. (ANL), Argonne, IL (United States), 2015-01
JOURNAL OF APPLIED PHYSICS, AMER INST PHYSICS, 2015
abstract
Abstract
The propagation of an incident shock and subsequent rarefaction and compression waves in a porous media are analysed from a set of large scale molecular dynamics simulations. The porous material is modelized by a collection of spherical pores, empty or filled with dense gaseous argon, enclosed in a copper matrix. We observe that the pore collapse induces a strong local disorder in the matrix even for shock intensities below the melting point of shocked copper. Various mechanisms are considered and a detailed analysis of the numerical results shows that the melting around an isolated pore is mainly due to the plastic work induced by the collapse: a result that can be extended to more complicated pore shapes. The systematic study of the influence of the shock intensity, the pore size, and the presence of a filling gas shows that the melting is mainly inhibited by the presence of the gas. The final structure strongly depends on the interactions between the waves resulting from the various reflections of the initial shock at the sample boundaries, implying that the evaluation of the incident shock intensity based on post-mortem analyses requires a knowledge of the full history of the sample. (C) 2015 AIP Publishing LLC.
JOURNAL OF APPLIED PHYSICS, AMER INST PHYSICS, 2015
abstract
Abstract
We present a series of molecular dynamics simulations of the shock compression of copper matrices containing a single graphite inclusion: these model systems can be related to some specific carbon-rich rocks which, after a meteoritic impact, are found to contain small fractions of nanodiamonds embedded in graphite in the vicinity of high impedance minerals. We show that the graphite to diamond transformation occurs readily for nanometer-sized graphite inclusions, via a shock accumulation process, provided the pressure threshold of the bulk graphite/diamond transition is overcome, independently of the shape or size of the inclusion. Although high diamond yields (similar to 80%) are found after a few picoseconds in all cases, the transition is non-isotropic and depends substantially on the relative orientation of the graphite stack with respect to the shock propagation, leading to distinct nucleation processes and size-distributions of the diamond grains. A substantial regraphitization process occurs upon release and only inclusions with favorable orientations likely lead to the preservation of a fraction of this diamond phase. These results agree qualitatively well with the recent experimental observations of meteoritic impact samples. (C) 2015 AIP Publishing LLC.
IMA Journal of Numerical Analysis, Volume 35, Issue 1, p. 454–477, 2015
Revue des Composites et des Matériaux Avancés, 2015
EAI Endorsed Transactions on Scalable Information Systems, ACM, 2015
abstract
Abstract
In this paper, an open and generic storage simulator is proposed. It simulates with accuracy multi-tiered storage systems based on heterogeneous devices including HDDs, SSDs and the connecting buses. The target simulated sys- tem is constructed from the hardware configuration input, then sent to the simulator modules along with the trace file and the appropriate simulator functions are selected and executed. Each module of the simulator is executed by a thread, and communicates with the others via ZeroMQ, a message transmission API using sockets for the information transfer. The result is an accurate behavior of the simulated system submitted to a specific workload and represented by performance and reliability metrics. No restriction is put on the input hardware configuration which can handle differ- ent levels of details and makes this simulator generic. The diversity of the supported devices, regardless to their na- ture: disks, buses, ..etc and organisation: JBOD, RAID, ..etc makes the simulator open to many technologies. The modularity of its design and the independence of its exe- cution functions, makes it open to handle any additional mapping, access, maintenance or reconstruction strategies. The conducted tests using OLTP and scientific workloads show accurate results, obtained in a competitive runtime.
2014
Int. J. Numer. Meth. Fluids, p. 1043-1063, 2014
Comp. Meth. Appl. Mech. Eng., Elsevier, p. 315-333, 2014
Computing, p. 263-278, 2014
Euro-Par 2014 Parallel Processing - 20th International Conference, Porto, Portugal, August 25-29, 2014. Proceedings, Springer, p. 596-607, 2014
21st European MPI Users’ Group Meeting, EuroMPI/ASIA ’14, Kyoto, Japan - September 09 - 12, ACM, p. 121, 2014
Finite Volumes for Complex Applications VII-Elliptic, Parabolic and Hyperbolic Problems, Springer International Publishing, p. 901-909, 2014
Communications in Computational Physics, 2014
2014
ROADEF - 15ème Congrès Annuel de La Société Française de Recherche Opérationnelle et d'aide à La Décision, Société française de recherche opérationnelle et d'aide à la décision, 2014
CSC 14, p. 2, 2014
AGU Fall Meeting Abstracts, p. IN21A-3700, 2014
Acta Applicandae Mathematicae, Volume 130, Issue 1, p. 151-162, 2014
Journal of the Acoustical Society of America 136(1), p. 37-52, 2014
Bulletin of the American Physical Society, 59(20), BAPS.2014.DFD.D20.3, 2014
Finite Volumes for Complex Applications VII-Elliptic, Parabolic and Hyperbolic Problems, 2014
abstract
Abstract
We are interested in the study of numerical schemes for the homogeneous in space asymptotic limit in the non equilibrium regime of the relativistic transfer equation. This limit leads to a frequency drift term modeling the Doppler effects for photons, and our aim is to design costless well-balanced schemes. One difficulty is that wave speed may vanish, which implies that standard well-balanced schemes constructed by discretizing the source term at the interfaces and by using a Godunov scheme may become inconsistent in this limit. This is indeed observed numerically.
Finite Elements in Analysis and Design, p. 23-33, 2014
abstract
Abstract
Simulation of low energy impacts on composite structures is a key feature in aeronautics. Unfortunately it involves very expensive numerical simulations: on the one side, the structures of interest have large dimensions and need fine volumic meshes (at least locally) in order to properly capture damage. On the other side, explicit simulations are commonly used to lead this kind of simulations (Lopes et al., 2009 [1]; Bouvet, 2009 [2]), which results in very small time steps to ensure the CFL condition (Courant et al., 1967 [3]). Implicit algorithms are actually more difficult to use in this situation because of the lack of smoothness of the solution that can lead to prohibitive number of time steps or even to non-convergence of Newton-like iterative processes. It is also observed that non-smooth phenomena are localized in space and time (near the impacted zone). It may therefore be advantageous to adopt a multiscale space/time approach by splitting the structure into several substructures with their own space/time discretization and their own integration scheme. The purpose of this decomposition is to take advantage of the specificities of both algorithms families: explicit scheme focuses on non-smooth areas while smoother parts (actually linear in this work) of the solutions are computed with larger time steps with an implicit scheme. We propose here an implementation of the Gravouil–Combescure method (GC) (Combescure and Gravouil, 2002 [4]) by the mean of low intrusive coupling between the implicit finite element analysis (FEA) code Zset/Zébulon (Z-set official website, 2013 [5]) and the explicit FEA code Europlexus (Europlexus official website, 2013 [6]). Simulations of low energy impacts on composite stiffened panels are presented. It is shown on this application that large time step ratios can be reached, thus saving computation time.
INSA de Lyon, 2014
IBISC, university of Evry / Paris-Saclay, 2014
abstract
Abstract
Distributed storage systems are nowadays ubiquitous, often under the form of multiple caches forming a hierarchy. A large amount of work has been dedicated to design, implement and optimise such systems. However, there exists to the best of our knowledge no attempt to use formal modelling and analysis in this field. This paper proposes a formal modelling framework to design distributed storage systems while separating the various concerns they involve like data-model, operations, placement, consistency, topology, etc. A system modelled in such a way can be analysed through model-checking to prove correctness properties, or through simulation to measure timed performance. In this paper, we define the modelling framework and then focus on timing analysis. We illustrate these two aspects on a simple example showing that our proposal has the potential to be used to make design decisions before the real system is implemented.
2013
Comp. Meth. Appl. Mech. Eng., Elsevier, p. 56-65, 2013
Euro-Par 2013: Parallel Processing Workshops - BigDataCloud, DIHC, FedICI, HeteroPar, HiBB, LSDVE, MHPC, OMHI, PADABS, PROPER, Resilience, ROME, and UCHPC 2013, Aachen, Germany, August 26-27, 2013. Revised Selected Papers, Springer, p. 168-177, 2013
42nd International Conference on Parallel Processing, ICPP 2013, Lyon, France, October 1-4, 2013, IEEE Computer Society, p. 985-994, 2013
Proceedings of the ACM SIGPLAN Workshop on Memory Systems Performance and Correctness, June, 21, 2013, Seattle, Washington, USA, Co-located with PLDI 2013, ACM, p. 3:1-3:9, 2013
Parallel Computing: Accelerating Computational Science and Engineering (CSE), Proceedings of the International Conference on Parallel Computing, ParCo 2013, 10-13 September 2013, Garching (near Munich), Germany, IOS Press, p. 783-792, 2013
SIAM Journal on Scientific Computing, 2013
Graph Partitioning, John Wiley & Sons, Ltd, p. 65-80, 2013
Proceedings of the 21st International Meshing Roundtable, Springer Berlin Heidelberg, p. 315-332, 2013
abstract
Abstract
Generating a full hexahedral mesh for any 3D geometric domain is still a challenging problem. Among the different attempts, the octree-based methods are the most efficient from an engineering point of view. But the main drawback of such methods is the lack of control near the boundary. In this work, we propose an a posteriori technique based on the notion of the fundamental mesh in order to improve the mesh quality near the boundary. This approach is based on the resolution of a constraint problem defined on the topology of the CAD model that we have to discretize.
Proceedings of the 6th International Conference on Adaptive Modeling and Simulation, ADMOS 2013, p. 412-422, 2013
abstract
Abstract
In numerous computational engineering applications, hexahedral meshes may be preferred over tetrahedral meshes. However, automatic hexahedral meshing remains an unsolved issue and thus generating a hexahedral mesh is known as a time-consuming stage that requires a lot of user interactions in the simulation process. A possible way for designing and optimizing a CAD model or a geometric shape requires parametric studies where the shape is enriched by inserting geometric details into it. Then we must \"adapt\" the initial mesh and not generate it anew for each new detail taken into account. In order to perform such studies with hexahedral meshes, we provide an imprinting method allowing us to automatically add geometric details into an existing mesh. This addition is done using geometric projections, sheets (layers of hexahedral elements) insertions and combinatorial algorithms while preserving the hexahedral mesh structure as best as possible.
Communications in Nonlinear Science and Numerical Simulation 18, p. 2679-2688, 2013
Maths in action, vol 6, n°2, p. 1-14, 2013
International Journal of Remote Sensing, 34(19), 6837–6864, 2013
abstract
Abstract
Hyperspectral imagery is a widely used technique to study atmospheric composition. For several years, many methods have been developed to estimate the abundance of gases. However, existing methods do not simultaneously retrieve the properties of aerosols and often use standard aerosol models to describe the radiative impact of particles. This approach is not suited to the characterization of plumes, because plume particles may have a very different composition and size distribution from aerosols described by the standard models given by radiative transfer codes. This article presents a new method to simultaneously retrieve carbon dioxide (CO2) and aerosols inside a plume, combining an aerosol retrieval algorithm using visible and near-infrared (VNIR) wavelengths and a CO2 estimation algorithm using shortwave infrared (SWIR) wavelengths. The microphysical properties of the plume particles, obtained after aerosol retrieval, are used to calculate their optical properties in the SWIR. Then, a database of atmospheric terms is generated with the radiative transfer code, Moderate Resolution Atmospheric Transmission (MODTRAN). Finally, pixel radiances around the 2.0 μm absorption feature are used to retrieve the CO2 abundances. After conducting a signal sensitivity analysis, the method was applied to two airborne visible/infrared imaging spectrometer (AVIRIS) images acquired over areas of biomass burning. For the first image, in situ measurements were available. The results show that including the aerosol retrieval step before the CO2 estimation: (1) induces a better agreement between in situ measurements and retrieved CO2 abundances (the CO2 overestimation of about 15%, induced by neglecting aerosols has been corrected, especially for pixels where the plume is not very thick); (2) reduces the standard deviation of estimated CO2 abundance by a factor of four; and (3) causes the spatial distribution of retrieved concentrations to be coherent.
11e colloque national en calcul des structures, 2013
COUPLED V: proceedings of the V International Conference on Computational Methods for Coupled Problems in Science and Engineering, CIMNE, p. 1373-1394, 2013
Chapman; Hall/CRC, 2013
abstract
Abstract
Contemporary High Performance Computing: From Petascale toward Exascale focuses on the ecosystems surrounding the world’s leading centers for high performance computing (HPC). It covers many of the important factors involved in each ecosystem: computer architectures, software, applications, facilities, and sponsors. The first part of the book examines significant trends in HPC systems, including computer architectures, applications, performance, and software. It discusses the growth from terascale to petascale computing and the influence of the TOP500 and Green500 lists. The second part of the book provides a comprehensive overview of 18 HPC ecosystems from around the world. Each chapter in this section describes programmatic motivation for HPC and their important applications; a flagship HPC system overview covering computer architecture, system software, programming systems, storage, visualization, and analytics support; and an overview of their data center/facility. The last part of the book addresses the role of clouds and grids in HPC, including chapters on the Magellan, FutureGrid, and LLGrid projects. With contributions from top researchers directly involved in designing, deploying, and using these supercomputing systems, this book captures a global picture of the state of the art in HPC.
2012
J. Comput. Phys., p. 4324-4354, 2012
J. Comput. Phys., p. 6559 - 6595, 2012
26th IEEE International Parallel and Distributed Processing Symposium, IPDPS 2012, Shanghai, China, May 21-25, 2012, IEEE Computer Society, p. 366-377, 2012
OpenMP in a Heterogeneous World - 8th International Workshop on OpenMP, IWOMP 2012, Rome, Italy, June 11-13, 2012. Proceedings, Springer, p. 254-257, 2012
Recent Advances in the Message Passing Interface - 19th European MPI Users’ Group Meeting, EuroMPI 2012, Vienna, Austria, September 23-26, 2012. Proceedings, Springer, p. 37-46, 2012
Laser and Particle Beams, p. 415-419, 2012
Phys. Rev. E, p. 066307, 2012
Discrete and Continuous Dynamical Systems S, AIMS, p. 345-367, 2012
Versailles Saint-Quentin-en-Yvelines University, France, 2012
19th International Conference on High Performance Computing, HiPC 2012, Pune, India, December 18-22, 2012, IEEE Computer Society, p. 1-10, 2012
International journal for numerical methods in engineering, Wiley Online Library, p. 1331-1357, 2012
Scientific Programming, Hindawi Ltd, p. 129-150, 2012
The Eighth International Conference on Engineering Computational Technology, p. 4, 2012
Parallel Partitioning, Coloring, and Ordering in Scientific Computing, Chapman & Hall/Crc Press, p. 351-371, 2012
Journal of Mathematical Sciences volume 185, p. 517–522, 2012
Asymptotic Analysis 79, p. 347–378, 2012
IEEE-AP, vol 60, n°11, p. 5286-5295, 2012
2011
2011
OpenMP in the Petascale Era - 7th International Workshop on OpenMP, IWOMP 2011, Chicago, IL, USA, June 13-15, 2011. Proceedings, Springer, p. 80-93, 2011
Esaim Proceedings, p. 195-210, 2011
Journal of Computational Physics, Elsevier, p. 1793-1821, 2011
Geophysical Journal International, p. 721-739, 2011-08
abstract
Abstract
We present forward and adjoint spectral-element simulations of coupled acoustic and (an)elastic seismic wave propagation on fully unstructured hexahedral meshes. Simulations benefit from recent advances in hexahedral meshing, load balancing and software optimization. Meshing may be accomplished using a mesh generation tool kit such as CUBIT, and load balancing is facilitated by graph partitioning based on the SCOTCH library. Coupling between fluid and solid regions is incorporated in a straightforward fashion using domain decomposition. Topography, bathymetry and Moho undulations may be readily included in the mesh, and physical dispersion and attenuation associated with anelasticity are accounted for using a series of standard linear solids. Finite-frequency Fréchet derivatives are calculated using adjoint methods in both fluid and solid domains. The software is benchmarked for a layercake model. We present various examples of fully unstructured meshes, snapshots of wavefields and finite-frequency kernels generated by Version 2.0 'Sesame' of our widely used open source spectral-element package SPECFEM3D.
Journal of Computational and Applied Mathematics 235, p. 5394–5410, 2011
Applied Numerical Mathematics 61, p. 1114-1131, 2011
Progress In Electromagnetics Research B, Vol. 29, p. 209-231, 2011
Remote Sensing of Environment 115(2):404-414, 2011
abstract
Abstract
Vegetation water content retrieval using passive remote sensing techniques in the 0.4–2.5 μm region (reflection of solar radiation) and the 8–14 μm region (emission of thermal radiation) has given rise to an abundant literature. The wavelength range in between, where the main water absorption bands are located, has surprisingly received very little attention because of the complexity of the radiometric signal that mixes both reflected and emitted fluxes. Nevertheless, it is now covered by the latest generation of passive optical sensors (e.g. SEBASS, AHS). This work aims at modeling leaf spectral reflectance and transmittance in the infrared, particularly between 3 μm and 5 μm, to improve the retrieval of vegetation water content using hyperspectral data. Two unique datasets containing 32 leaf samples each were acquired in 2008 at the USGS National Center, Reston (VA, USA) and the ONERA Research Center, Toulouse (France). Reflectance and transmittance were recorded using laboratory spectrometers in the spectral region from 0.4 μm to 14 μm, and the leaf water and dry matter contents were determined. It turns out that these spectra are strongly linked to water content up to 5.7 μm. This dependence is much weaker further into the infrared, where spectral features seem to be mainly associated with the biochemical composition of the leaf surface. The measurements show that leaves transmit light in this wavelength domain and that the transmittance of dry samples can reach 0.35 of incoming light around 5 μm, and 0.05 around 11 μm. This work extends the PROSPECT leaf optical properties model by taking into account the high absorption levels of leaf constituents (by the insertion of the complex Fresnel coefficients) and surface phenomena (by the addition of a top layer). The new model, PROSPECT-VISIR (VISible to InfraRed), simulates leaf reflectance and transmittance between 0.4 μm and 5.7 μm (at 1 nm spectral resolution) with a root mean square error (RMSE) of 0.017 and 0.018, respectively. Model inversion also allows the prediction of water (RMSE = 0.0011 g/cm²) and dry matter (RMSE = 0.0013 g/cm²) contents.
2010
Int. J. Finite Volumes, p. 30-65, 2010
24th IEEE International Symposium on Parallel and Distributed Processing, IPDPS 2010, Atlanta, Georgia, USA, 19-23 April 2010 - Workshop Proceedings, IEEE, p. 1-7, 2010
Beyond Loop Level Parallelism in OpenMP: Accelerators, Tasking and More, 6th Internationan Workshop on OpenMP, IWOMP 2010, Tsukuba, Japan, June 14-16, 2010, Proceedings, Springer, p. 1-14, 2010
Comptes Rendus Académie des Sciences, Paris, Série I, p. 105-110, 2010
Comptes Rendus Mathématique, Elsevier, p. 1027-1032, 2010
ESAIM: Mathematical Modelling and Numerical Analysis, EDP Sciences, p. 693-713, 2010
Transactions on Computer Science, LNCS 5890, p. 122-131, 2010
ESAIM-Mathematical Modelling and Numerical Analysis, Volume 44, number 6, p. 1279-1293, 2010
p. 1279-1293, 2010
abstract

Abstract
Abstract This paper presents a new method, called Mesh Matching, for handling non-conforming hexahedral-to-hexahedral interfaces for finite element analysis. Mesh Matching modifies the hexahedral element topology on one or both sides of the interface until there is a one-to-one pairing of finite element nodes, edges and quadrilaterals on the interface surfaces, allowing mesh entities to be merged into a single conforming mesh. Element topology is modified using hexahedral dual operations, including pillowing, sheet extraction, dicing and column collapsing. The primary motivation for this research is to simplify the generation of unstructured all-hexahedral finite element meshes. Mesh Matching relaxes global constraint propagation which currently hinders hexahedral meshing of large assemblies, and limits its extension to parallel processing. As a secondary benefit, by providing conforming mesh interfaces, Mesh Matching provides an alternative to artificial constraints such as tied contacts and multi-point constraints. The quality of the resultant conforming hexahedral mesh is high and the increase in number of elements is moderate. Copyright © 2009 John Wiley & Sons, Ltd.
2009
J. Comput. Phys., p. 5160-5183, 2009
ESAIM: Proc., p. 1008-1024, 2009
Recent Advances in Parallel Virtual Machine and Message Passing Interface, 16th European PVM/MPI Users’ Group Meeting, Espoo, Finland, September 7-10, 2009. Proceedings, Springer, p. 94-103, 2009
Physics of Plasmas, p. 044502, 2009
Journal of Computational Physics, p. 833-860, 2009
Computers & Fluids, Elsevier, p. 765-777, 2009
Proceedings of the 8th Workshop on Parallel/High-Performance Object-Oriented Scientific Computing, Association for Computing Machinery, 2009
abstract
Abstract
In this paper, we introduce the Arcane software development framework for 2D and 3D numerical simulation codes. First, we describe the Arcane core, the mesh management and the parallelism strategy. Then, we focus on the concepts introduced to speed up the development of numerical codes: numerical modules, variables, entry points and services. We explain the execution model and enumerate the available debugging tools. Finally, the main functionalities of Arcane are described through an example. As a conclusion, we present the future works.
Journal of computational Physics, Elsevier, p. 5763-5786, 2009
Journal of Physics: Conference Series, p. 12008, 2009-07
Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), p. 191-205, 2009
2009
Proc. of 2009 Dagstuhl Seminar on Combinatorial Scientific Computing, 2009
Remote Sensing of Environment 113(4):781-793, 2009
abstract
Abstract
This paper presents the retrieval method L-APOM which aims at characterizing the microphysical and optical properties of aerosol plumes from hyperspectral images with high spatial resolution. The inversion process is divided into three steps: estimation of the ground reflectance below the plume, characterization of the standard atmosphere (gases and background aerosols) and estimation of the plume aerosols properties. As using spectral information only is not sufficient to insure uniqueness of solutions, original constraints are added by assuming slow spatial variations of particles properties within the plume. The whole inversion process is validated on a large set of simulated images and reveals to remain accurate even in the worst cases of noise: relative estimation errors of aerosol properties remain between 10% and 20% in most cases. L-APOM is applied on a real AVIRIS hyperspectral image of a biomass burning plume for which in situ measurements are available. Retrieved properties appear globally consistent with measurements.
USENIX Association, 2009
2008
Comput. Fluids, p. 877 - 886, 2008
Euro-Par 2008 Workshops - Parallel Processing, VHPC 2008, UNICORE 2008, HPPC 2008, SGS 2008, PROPER 2008, ROIA 2008, and DPA 2008, Las Palmas de Gran Canaria, Spain, August 25-26, 2008, Revised Selected Papers, Springer, p. 53-62, 2008
Euro-Par 2008 - Parallel Processing, 14th International Euro-Par Conference, Las Palmas de Gran Canaria, Spain, August 26-29, 2008, Proceedings, Springer, p. 78-88, 2008
High Performance Computing - HiPC 2008, 15th International Conference, Bangalore, India, December 17-20, 2008. Proceedings, Springer, p. 30-41, 2008
ESAIM: Proceedings, EDP Sciences, p. 46-59, 2008
Comptes Rendus Mathematique, Elsevier, p. 533-538, 2008
International journal for numerical methods in engineering, Wiley Online Library, p. 1065-1089, 2008
2008
Finite Volumes for Complex Applications V, John Wiley & Sons, p. 851-864, 2008
Journal of Computational Physics, Elsevier, p. 9365-9388, 2008
Proposed for publication in Parallel Computing., Sandia National Laboratories (SNL), Albuquerque, NM, and Livermore, CA (United States), 2008-12
Parallel Computing, p. 318-331, 2008
High Performance Computing for Computational Science - VECPAR, Springer, p. 350-363, 2008
abstract
Abstract
In order to better understand the internal structure of asteroids orbiting in the Solar system and then the response of such objects to impacts, seismic wave propagation in asteroid 433-Eros is performed numerically based on a spectral-element method at frequencies lying between 2 Hz and 22 Hz. In the year 2000, the NEAR Shoemaker mission to Eros has provided images of the asteroid surface, which contains numerous fractures that likely extend to its interior. Our goal is to be able to propagate seismic waves resulting from an impact in such models. For that purpose we create and mesh both homogeneous and fractured models with a highly-dispersive regolith layer at the surface using the CUBIT mesh generator developed at Sandia National Laboratories (USA). The unstructured meshes are partitioned using the METIS software package in order to minimize edge cuts and therefore optimize load balancing in our parallel blocking or non-blocking MPI implementations. We show the results of several simulations and illustrate the fact that they exhibit good scaling.
SC '08: Proceedings of the 2008 ACM/IEEE Conference on Supercomputing, p. 1-11, 2008-11
abstract
Abstract
SPECFEM3D_GLOBE is a spectral element application enabling the simulation of global seismic wave propagation in 3D anelastic, anisotropic, rotating and self-gravitating Earth models at unprecedented resolution. A fundamental challenge in global seismology is to model the propagation of waves with periods between 1 and 2 seconds, the highest frequency signals that can propagate clear across the Earth. These waves help reveal the 3D structure of the Earth's deep interior and can be compared to seismographic recordings. We broke the 2 second barrier using the 62K processor Ranger system at TACC. Indeed we broke the barrier using just half of Ranger, by reaching a period of 1.84 seconds with sustained 28.7 Tflops on 32K processors. We obtained similar results on the XT4 Franklin system at NERSC and the XT4 Kraken system at University of Tennessee Knoxville, while a similar run on the 28K processor Jaguar system at ORNL, which has better memory bandwidth per processor, sustained 35.7 Tflops (a higher flops rate) with a 1.94 shortest period.Thus we have enabled a powerful new tool for seismic wave simulation, one that operates in the same frequency regimes as nature; in seismology there is no need to pursue periods much smaller because higher frequency signals do not propagate across the entire globe.We employed performance modeling methods to identify performance bottlenecks and worked through issues of parallel I/O and scalability. Improved mesh design and numbering results in excellent load balancing and few cache misses. The primary achievements are not just the scalability and high teraflops number, but a historic step towards understanding the physics and chemistry of the Earth's interior at unprecedented resolution.
Wave Motion 45, p. 400-411, 2008
IEEE Transactions on Antennas Propagation, p. 1984-1992, 2008
International Journal of Finite Volumes, V. 5, p. 1-16, 2008
Applied Optics 47(11):1851-1866, 2008
abstract
Abstract
A semianalytical model, named APOM (aerosol plume optical model) and predicting the radiative effects of aerosol plumes in the spectral range [0.4,2.5 μm], is presented in the case of nadir viewing. It is devoted to the analysis of plumes arising from single strong emission events (high optical depths) such as fires or industrial discharges. The scene is represented by a standard atmosphere (molecules and natural aerosols) on which a plume layer is added at the bottom. The estimated at-sensor reflectance depends on the atmosphere without plume, the solar zenith angle, the plume optical properties (optical depth, single-scattering albedo, and asymmetry parameter), the ground reflectance, and the wavelength. Its mathematical expression as well as its numerical coefficients are derived from MODTRAN4 radiative transfer simulations. The DISORT option is used with 16 fluxes to provide a sufficiently accurate calculation of multiple scattering effects that are important for dense smokes. Model accuracy is assessed by using a set of simulations performed in the case of biomass burning and industrial plumes. APOM proves to be accurate and robust for solar zenith angles between 0° and 60° whatever the sensor altitude, the standard atmosphere, for plume phase functions defined from urban and rural models, and for plume locations that extend from the ground to a height below 3 km. The modeling errors in the at-sensor reflectance are on average below 0.002. They can reach values of 0.01 but correspond to low relative errors then (below 3% on average). This model can be used for forward modeling (quick simulations of multi/hyperspectral images and help in sensor design) as well as for the retrieval of the plume optical properties from remotely sensed images.
2007
Int. J. Multiphase Flow, p. 1 - 39, 2007
Plasma Physics and Controlled Fusion, p. B601-B610, 2007
Shock compression of condensed matter, p. 47-50, 2007
Journal of Computational Physics, p. 464-490, 2007
Computer Methods in Applied Mechanics and Engineering, p. 3127-3140, 2007
APS shock compression of condensed matter meeting abstracts, p. G4.004, 2007
Numerical Analysis and Scientific Computing for PDEs and their challenging applications, 2007
Computer methods in applied mechanics and engineering, Elsevier, p. 2497-2526, 2007
PPAM 2007 - Seventh International Conference on Parallel Processing and Applied Mathematics, 2007-09
Université Sciences et Technologies - Bordeaux I, 2007-09
IEEE Xplore, 2007
abstract
Abstract
This letter presents a new theoretical approach for anomaly detection using a priori information about targets. This a priori knowledge deals with the general spectral behavior and the spatial distribution of targets. In this letter, we consider subpixel and isolated targets that are spectrally anomalous in one region of the spectrum but not in another. This method is totally different from matched filters that suffer from a relative sensitivity to low errors in the target spectral signature. We incorporate the spectral a priori knowledge in a new detection distance, and we propose a Bayesian approach with a Markovian regularization to suppress the potential targets that do not respect the spatial a priori. The interest of the method is illustrated on simulated data consisting in realistic anomalies that are superimposed on a real HyMap hyperspectral image.
WiP session at FAST'97, 2007
Proceedings of the Linux Symposium, p. 113-124, 2007
2006
These de doctorat, spécialité informatique, CEA, Université de Bordeaux, 2006
Physics of Plasmas, p. 122701, 2006
Comptes Rendus Mathematique, Elsevier, p. 441-446, 2006
Euro-Par 2006 Parallel Processing, Springer, p. 243-252, 2006
PIER 59, p. 215-230, 2006
La Recherche, 2006
IEEE Transactions on Geoscience and Remote Sensing 44(6):1566 - 1574, 2006
abstract
Abstract
A method [atmospheric correction via simulated annealing (ACSA)] is proposed that enhances the atmospheric correction of hyperspectral images over dark surfaces. It is based on the minimization of a smoothness criterion to avoid the assumption of linear variations of the reflectance within gas absorption bands. We first show that this commonly used approach generally fails over dark surfaces when the signal to noise ratio strongly declines. In this case, important residual features highly correlated with the shape of gas absorption bands are observed in the estimated surface reflectance. We add a geometrical constraint to deal with this correlation. A simulated annealing approach is used to solve this constrained optimization problem. The parameters involved in the implementation of the algorithm (initial temperature, number of iterations, cooling schedule, and correlation threshold) are automatically determined by using a standard simulated annealing theory, reflectance databases, and sensor characteristics. Applied to a HyMap image with available ground truths, we verify that ACSA adequately recovers ground reflectance over clear land surfaces, and that the added spectral shape constraint does not introduce any spurious feature in the spectrum. The analysis of an AVIRIS image of Central Switzerland clearly shows the ability of the method to perform enhanced water vapor estimations over dark surfaces. Over a lake (reflectance equal to 0.02, low signal to noise ratio equal to about 6), ACSA retrieves unbiased water vapor amounts (2.86 cm/spl plusmn/0.36 cm) in agreement with in situ measurements (2.97 cm/spl plusmn/0.30 cm). This corresponds to a reduction of the standard deviation by a factor 3 in comparison with standard unconstrained procedures (1.95 cm/spl plusmn/1.08 cm). Similar results are obtained using a Hyperion image of DoE ARM SGP test site containing a very dark area of the land surface.
2005
Theor. Comput. Fluid Dyn., p. 197-227, 2005
Numerical Methods for Hyperbolic and Kinetic Problems, IRMA lectures in Mathematics and Theoretical Physics, p. 177-207, 2005
IEE Press, 2005
Annales des Télécomm, vol.60, n°5-6, p. 630-648, 2005
SIAM journal of numerical analysis, vol.43, n°2, p. 578-603, 2005
In F. Benkhaldoun, D. Ouazar, S. Raghay, Finite volumes for complex applications IV, Problems and perspectives, p. 225-236, 2005
M.I.S.C, 2005
2004
Arch. Comput. Methods Eng., p. 199-256, 2004
AIAA J., New York, etc. American Institute of Aeronautics; Astronautics., p. 469-477, 2004
Journal of Computational Physics, p. 80-105, 2004
Computational Geosciences, Springer, p. 149-162, 2004
Proceedings of the 5th Eurographics conference on Parallel Graphics and Visualization, Eurographics Association, p. 49-58, 2004
Comptes Rendus Mathematique, Elsevier, p. 893-898, 2004
La Recherche, 2004
IEEE Transactions on Geoscience and Remote Sensing 42(4):854-864, 2004
abstract
Abstract
A method [joint reflectance and gas estimator (JRGE)] is developed to estimate a set of atmospheric gas concentrations in an unknown surface reflectance context from hyperspectral images. It is applicable for clear atmospheres without any aerosol in a spectral range between approximately 800 and 2500 nm. Standard gas by gas methods yield a 6% rms error in H/sub 2/O retrieval from Airborne Visible/Infrared Imaging Spectrometer (AVIRIS) data, reaching several tens percent for a set of widespread ground materials and resulting from an simplifying assumption of linear variations of the reflectance model within gas absorption bands and partial accounting of the gas induced signal. JRGE offers a theoretical framework consisting in a two steps algorithm that accounts for sensor characteristics, assumptions on gas concentrations and reflectance variations. It estimates variations in gas concentrations relatively to a standard atmosphere model. An adaptive cubic smoothing spline like estimation of the reflectance is first performed. Concentrations of several gaseous species are then simultaneously retrieved using a nonlinear procedure based on radiative transfer calculations. Applied to AVIRIS spectra simulated from reflectance databases and sensor characteristics, JRGE reduces the errors in H/sub 2/O retrieval to 2.87%. For an AVIRIS image acquired over the Quinault prescribed fire, far field CO/sub 2/ estimate (348 ppm, about 6% to 7% rms) is in agreement with in situ measurement (345-350 ppm) and aerosols yield an underestimation of total atmospheric CO/sub 2/ content equal to 5.35% about 2 km downwind the fire. JRGE smoothes and interpolates the reflectance for gas estimation but also provides nonsmoothed reflectance spectra. JRGE is shown to preserve various mineral absorption features included in the AVIRIS image of Cuprite Mining District test site.
2003
Numerical methods for scientific computing variational problems and applications, Barcelona, 2003
Computer methods in applied mechanics and engineering, Elsevier, p. 1939-1959, 2003
Applied Math Letters 16, p. 147-154, 2003
Linux Magazine, Diamond Editions, 2003
2002
J. Comput. Phys., p. 301 - 336, 2002
Mathematical Modeling and Numerical Simulation in Continuum Mechanics, Springer, p. 125-135, 2002
Numéro spécial du journal SMF SMAI, “l’explosion des mathématiques", 2002
Thèse de doctorat en Mécanique. Université Pierre et Marie Curie - Paris VI, 2002. ⟨tel-00006002⟩, 2002
2001
ESAIM: Proceedings, EDP Sciences, p. 267-275, 2001
2000
Int. J. Nonlin. Sci. Num., p. 285-298, 2000
Comptes Rendus de l'Académie des Sciences-Series I-Mathematics, Elsevier, p. 1107-1111, 2000
Journal of computational Physics, Elsevier, p. 481-499, 2000
1998
Comptes Rendus de l'Academie des Sciences Series I Mathematics, p. 1433-1436, 1998
Theoretical Computer Science, p. 31-44, 1998
abstract
Abstract
Program environments are now commonly used for parallelism on networks of workstations. There is a need for simple and consistent tools to measure algorithm performance on heterogeneous networks. In this work we propose a generalization to heterogeneous networks of the classical efficiency formula E(N) = S(N)N, where S(N) is the speedup on N processors.
1997
Parallel Computing, p. 165-180, 1997
abstract
Abstract
We present in this paper the strong points and limitations of semi-automatic parallelization, data parallel programming and message passing programming. We apply these on two numerical algorithms namely a bi-dimensional Fourier transform algorithm and a conjugate gradient programs. We implemented this program for each of the different methods on a Cray T3D. The results of these experiments demonstrate the accuracy of our proposition that when the three methods are combined, efficiency, portability and easiness of parallel programming may be achieved.
International Journal of Foundations of Computer Science, p. 211-235, 1997
Springer Verlag, 1997
Progress in Electromagnetic Research 16, 1997
Annales des Télécomm., 9-10, p. 483-488, 1997
1996
Euro-Par'96 Parallel Processing, Springer Berlin Heidelberg, p. 651-664, 1996
abstract
Abstract
Program environments are now commonly used for parallelism on networks of workstations. That is the reason why there is a need for simple and consistent tools to measure algorithm performance on heterogeneous networks. In this work we propose a generalization to heterogeneous networks of the classical efficiency formula E(N)=S(N)/N, where S(N) is the speedup on N processors.
Parallel Computing, p. 289-310, 1996
abstract
Abstract
We propose in this paper a new parallel algorithm for computing the matrix-vector product on a ring of p processors. This solution allows to overlap as much communications as possible. Some simulations and experiments on a Paragon are given in order to confirm the interest in this algorithm.
Parallel Computing, p. 1413-1427, 1996
abstract
Abstract
We present in this paper the results of various communication benchmarks on a Cray T3D MPP system. They are composed of most-used communication schemes in parallel applications and numerical kernels. They have been implemented using PVM message-passing libraries on the Cray T3D system. For each of these benchmarks, we propose a model depending on the size of the message communicated and the number of processors involved. We verify that the error between the proposed model and the measures is very small (0.8% in average for point-to-point communications and 3% in average for collective communications).
Annales des Télécomm., 3-4, p. 137-142, 1996
1995
High-Performance Computing and Networking, Springer Berlin Heidelberg, p. 600-605, 1995
abstract
Abstract
We present in this paper general techniques for overlapping communications in parallel numerical kernels. We describe first some dependencies schemes which can be found in most of numerical parallel algorithms and we apply on these schemes methods based on the change of the granularity of the computational tasks. The choice of the granularity in order to obtain a good overlap depends on the main parameters of the target machines. We apply the precedent techniques of overlapping on classical numerical kernels, namely the matrix-vector product and the bi-dimensional FFT, and implemented them on a T3D and a Paragon. The results of these experiments demonstrate the accuracy of this approach.
Journal of Electromagnetic Waves and Applications JEWA 9, p. 503-520, 1995
Journal of Electromagnetic Waves and Applications JEWA 9, p. 905-924, 1995
Numéro spécial des annales des télécomm, 1995
1994
Parallel Processing: CONPAR 94 --- VAPP VI, Springer Berlin Heidelberg, p. 605-615, 1994
abstract
Abstract
This paper presents an overlapping technique of communications by computations based on pipelined communications. This allows to improve the execution time of most parallel numerical algorithms. Some simple examples are developed to illustrate the efficiency of this technique matrix-vector product and bi-dimensional Fast Fourier Transform. Moreover, we propose an unified formalism to express easily the pipelined versions of these algorithms. Finally, we report some experiments on various parallel machines.
SMAI, Springer Verlag, vol 16, 1994
Annales des Télécomm. , 3-4, p. 194-198, 1994
Annales des Télécomm. , 3-4, p. 199-204, 1994
Annales des Télécomm. , 3-4, p. 205-210, 1994
1993
Proceedings The 2nd International Symposium on High Performance Distributed Computing, p. 121-128, 1993
IEEE AP, 1993
Revue Science et Défense, p. 89-124, 1993
Proceedings of IEEE, p. 1656-1684, 1993
Radio Science, p. 527-531, 1993
1992
Annales des Télécomm, n°47, p. 391-399, 1992
Annales des Télécomm, n°47, p. 400-412, 1992
Annales des Télécomm, n°47, p. 413-420, 1992
abstract
Abstract
On considère un objet axisymétrique illuminé par une onde plane en incidence axiale. Les champs de surface dans la zone d'ombre sont dus aux ondes rampantes et sont donnés, loin de l' axe de symétrie, par les formules de la théorie géométrique de la diffraction. Le point sur l' axe de symétrie est un foyer pour les ondes rampantes et les formules précédentes y prédisent un résultat infini. On détermine, à l'aide d' une méthode de développement asymptotique, une solution pour les champs au voisinage du foyer. Cette solution tend vers les résultats de la TGD loin du foyer et reste bornée au foyer. La comparaison des résultats obtenus par équation intégrale sur des sphéroïdes allongés ou aplatis est satisfaisante.
Journal d’Acoustique, 5, p. 507-530, 1992
IEEE AP, vol 40, n°10, p. 1165-1174, 1992
IEEE Trans MTT, vol 40, p. 1789-1796, 1992
1991
Annales des Télécomm, 7-8, p. 388-391, 1991
Mathematical and numerical aspects of wave propagation phenomena G. Cohen, L. Halpern, P. Joly, Ed, Siam, 1991
Annales des Télécomm, 7-8, p. 382-387, 1991